ASAC 빅데이터 분석가 7기/ASAC 일일 기록
ASAC 빅데이터 분석가 과정 15일차 - 2 (24.12.24)
junslee
2024. 12. 24. 16:11
18_na
- pandas 에서 결측치 데이터에 대한 처리
=> pandasd에서 결측치로 인정한 경우에 대해서만 - nan,"",None => 유의해서 처리를 해야한다
- 1. 빵구난 데이터가 있다면 EDA에서도 처리할 때 이슈
- ML 모델을 반듯이 처리를 해야함
처리방법1) 빵구난 데이터를 지우자 : dropna
- 경우에 따라서 데이터가 많이 줄어들 수 있다
처리방법2) 빵구난 데이터를 채우자 : 정답은 없다
- 분석자가 주관적으로 해야함
- 1개 대표값 : 평균, 중앙값, 최빈값 etc
- 유사한 데이터를 보고 추정
- 있는 값들을 대상으로 모델을 만들어서 예측
(정답은 없음) - 참고)
특정한 줄(가로,세로)을 지울 떄 : drop
nan이 있는 데이터를 지울 때 : dropna
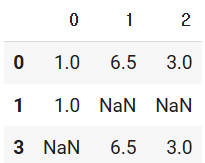
from numpy import nan as NA
import pandas as pd
data = pd.DataFrame(
data=[
[1,6.5,3],
[1,NA,NA],
[NA,NA,NA],
[NA,6.5,3]
]
)
data

dropna
data.dropna()
# 가로줄에 대해서 모든 정보가 있는 경우만 살린다
# (모든 설문에 응답한 사람만)
# 장점 : 샘플이 모든 속성을 다 가지고 있다
# 단점 : 샘플의 수가 많이 줄어들 수 있다

data.dropna( axis=0)

data.dropna( axis=1)
# 세로줄 기준으로 모든 가로줄의 값이 있는 것만 살린다

- dropna에서
- axis : 가로줄/세로줄에서 데이터들이 다 있는지 체크
(axis=0/1)
- how="all" : 완전히 빵구난 데이터만 제거
- thresh : 정상적인 데이터가 살아 있는 기준의 수
data.dropna(axis=0)

data.dropna(axis=0, how="all")

data.dropna(axis=0, thresh=1)
=> 가로줄 기준으로 모든 컬럼들에 대해서 정상적인 값이 1개 이상이면 살리자
fillna
- 채우자 fillna --> nan으로 되어 있는 친구들을 채우자
data.fillna(99)

- 1번 컬럼에 대해서 혹시 누락된 값이 있다면 0으로 채우고
2번 컬럼에 대해서 혹시 누락된 값이 있다면 99로 채우고 싶다
data.fillna({0:0, 1:99})

- 마무리
나중에는 여러가지 방식으로 채우는 것들을 할 예정이다
대표값, 유사한 값의 대표값, 기타 여러 방식들이 존재한다
99_cheatsheet
- 참고
처음에 뭐를 배워야 뭔가를 하는데
파이썬, pandas,sql + 개인 eda
주제 + 데이터 가지고
kaggle, dacon 대회 열어둔 데이터 : 개인 포폴이므로 참고만 하자
=> 주제에 대한 힌트
직접 날 데이터를 수집할 수 있도록 해야 함
(사이트,api) :국가
19_
- 지금 기존의 DF의 모양을 변경하자
=> 내가 보고 싶은 항목들을 중심으로 다시 세팅
기준 : 내가 보고자 하는 속성/컬럼/요소
위의 방식의 가장 대표적 : 엑셀 -- 피봇테이블
=> 각각의 데이터/샘플 단위로 보는 것이 아니라
내가 원하는 속성/컬럼 기준대로 다시 보자
=> EDA 핵심적인 부분중에 하나
import numpy as np
import pandas as pd
# 11.sale 데이터
!gdown 162ojCdYDDnxcadWUN57e7eM0_3E5ac9y
Downloading...
From: https://drive.google.com/uc?id=162ojCdYDDnxcadWUN57e7eM0_3E5ac9y
To: /content/11_sales-funnel.xlsx
100% 5.68k/5.68k [00:00<00:00, 18.8MB/s]
path = '/content/11_sales-funnel.xlsx'
data = pd.read_excel(path, sheet_name="Sheet1")
data.head()

- 데이터에 대한 설명
- Account : 고객의 계좌 번호
- Name : 고객의 성함
- Rep : 영업 담당자( 실무 영업사원 )
- Manager : 영업 담당자의 팀장
- Product : 판매한 물건
- Quantity : 판매한 물건의 수량
- Price : 판매한 물건의 가격
- Status : 현재 주문에 대한 상태 - 목적 : 매출 관련된 데이터를 중심으로 인사 평가를 해보자
=> 본인이 인사팀장의 관점으로 바라보 된다 - pivot_table 을 활용을 해서 새롭게 판을 짜려고 한다
1. 가로에 무엇을 --> 대상
2. 세로에 무엇을 --> 어떤 속성
3. 1/2로 만들어진 새로운 공간을 어떻게 채울지
=> 여러 개의 원본 데이터들 어떻게 집계처리를 해서 대표화한다
- Q) 팀장들에 대해서 팀에 속한 매출액을 보고 싶다
--> 평가의 기준이 오로지 매출이다
--> 값들에 대해서 특별하게 지정하지 않으면 : 평균
pd.pivot_table( data,
index=["Manager"],
values=["Price"])
# 값을 채우는 방식에는 특별한 언급을 안 하면 : 평균

pd.pivot_table( data,
index=["Manager"],
values=["Price"],
aggfunc=["mean"])

- Q) 영업 팀장별로 , 총 매출액의 합을 보자
pd.pivot_table( data,
index=["Manager"],
values=["Price"],
aggfunc=["sum"])

- Q) 영업 팀장별로 속한 "영원사원"을 기준으로 각 영업사원들의 총 매출액을 보자
pd.pivot_table( data,
index=["Manager","Rep"],
values=["Price"],
aggfunc=["sum"])
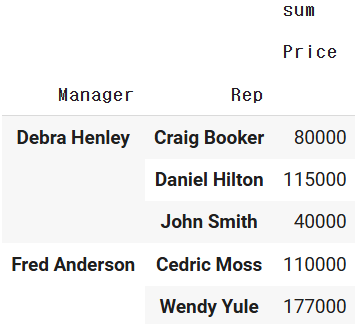
pd.pivot_table( data,
index=["Rep","Manager"],
values=["Price"],
aggfunc=["sum"])

- Q) 단순 총 매출액만 보고 판단하는것이 아닌가 해서
=> 꾸준한 영업활동을 하면서 올린 매출인지, 운이 좋아서 크게 1건을 한 것인지 좀 보자
pd.pivot_table( data,
index=["Manager","Rep"],
values=["Price"],
aggfunc=["sum", "count"])

- Q) 상품기획/평가
=> 매출 실적에 대해서 보기는 하는데 구체적으로 회사의 어느 상품군을 잘 팔고 잘 못파는지
pd.pivot_table( data,
index=["Manager","Rep"],
values=["Price"], # 일반적인 수치형 컬럼
columns =["Product"], # 카테고리형 컬럼
aggfunc=["sum"])

- 잘개 여러 항목으로 보면 디테일하게 볼 수는 있다
빈칸이 생길 확률이 높아진다 (NaN 나타날 확률이 높다)
pd.pivot_table( data,
index=["Manager","Rep"],
values=["Price"],
columns =["Product"],
aggfunc=["sum"],
fill_value=0)

- 참고) 내가 보고자 하는 속성을 좀 늘려보자
(기존 속성 : price)
+ 판매 수량 Quantity
+ 상품별로 쪼개서
pd.pivot_table( data,
index=["Manager","Rep"],
values=["Price","Quantity"],
columns =["Product"],
aggfunc=["sum"],
fill_value=0,margins=True)

- 총계 처리에 대한 보이기
pd.pivot_table( data,
index=["Manager","Rep"],
values=["Price","Quantity"],
columns =["Product"],
aggfunc=["sum"],
fill_value=0,
margins=True)

- 집계 처리를 하는 방식이 price => mean, sum (평균매출액, 누적매출액)
quantity는 sum(누적매출량) => Dict
pd.pivot_table( data,
index=["Manager","Rep"],
values=["Price","Quantity"],
columns =["Product"],
aggfunc={
"Price":["mean","sum"],
"Quantity":["sum"]
},
fill_value=0)

- pivot_table의 목적
=> 수집된 데이터를 내가 보고자 하는 "항목/속성/기준"으로 바라보자
: 새롭게 2차원의 판을 짬
가로 : index
세로 : values +항목별로 쪼개서 : columns
=> aggfunc : 새롭게 짠 판에 값을 어찌 채울지
=> 수집한 데이터에 숨겨진 속성/내용/의미들을 탐색 - cf) pandas에 DF 재형성할 떄 : pivot_table, groupby
=> groupby를 주로 사용
pivot_table:엑셀 사용자를 위한 툴
groupby : sql 사용자를 위한 툴
- pandas 에서 기본적인 기능에 대해서는 꼭 리뷰/ 정리
- 개인 프로젝트 데이터를 구체적으로 찾아보세요 + 수집 방법
=> pandas + sql