ASAC 빅데이터 분석가 7기/DL(Deep Learning)
Deep Learning 개요
junslee
2025. 2. 10. 14:53
20 Deep Learning applications
- Self Driving Cars 자율 주행차
딥러닝은 자율주행차의 핵심 기술로, 신경망과 컴퓨터 비전을 활용해 객체 감지, 도로 주행, 교통 표지판 인식, 장애물 회피 등을 가능하게 합니다. - Entertainment 엔터테인먼트
넷플릭스, 스포티파이, 유튜브와 같은 플랫폼은 딥러닝 기반 추천 시스템을 활용해 사용자의 시청/청취 패턴을 분석하고 개인화된 콘텐츠를 제공합니다. - Visual Recognition 시각적 인식
합성곱 신경망(CNN)과 같은 딥러닝 모델은 이미지 및 비디오에서 객체를 식별하고 분류하는 데 뛰어나며, 이를 보안, 의료, 소매업 등 다양한 산업에 적용할 수 있습니다. - Virtual Assistants 가상 비서
시리, 구글 어시스턴트, 알렉사와 같은 가상 비서는 딥러닝을 활용해 자연어 명령을 처리하고, 음성 인식 기능을 개선하며, 정확한 응답을 제공합니다. - Fraud Detection 사기 탐지
딥러닝 알고리즘은 금융 거래의 패턴과 비정상적인 점을 분석해 은행 및 전자 상거래에서 사기를 탐지하고 방지하는 데 기여합니다. - Natural Language Processing 자연어(NLP) 처리
딥러닝은 감정 분석, 언어 생성, 번역, 질문 응답, 챗봇 기능 등 자연어 처리 작업을 지원하며, BERT와 GPT와 같은 모델이 이를 주도합니다. - News Aggregation and Fraud News Detection 뉴스 수집 및 가짜 뉴스 탐지
딥러닝 알고리즘은 뉴스 기사를 주제별로 클러스터링하고, 작성 패턴과 출처의 신뢰성을 분석하여 가짜 뉴스를 탐지합니다. - Detecting Developmental Delay in Children 아동 발달 지연 탐지
의료 연구자들은 딥러닝 모델을 활용해 아동의 발달 패턴을 분석하고 자폐증, ADHD 및 기타 발달 장애의 초기 징후를 감지합니다. - Colourisation of Black and White images 흑백 이미지 컬러화
고급 딥러닝 모델은 흑백 사진이나 비디오를 자동으로 컬러화하며, 역사적 이미지를 현실감 있게 복원합니다. - Adding sounds to silent movies 무성영화에 소리 추가
딥러닝 기술을 활용하면 시각적 콘텐츠를 기반으로 주변음을 인식하고 시뮬레이션하여 무성영화에 오디오를 재현할 수 있습니다. - Healthcare 헬스케어
딥러닝은 암 진단, 의료 영상에서의 이상 탐지, 환자 예후 예측, 로봇 수술 시스템 등에 활용되어 의료 분야를 혁신합니다. - Personalisations 개인화
전자상거래 플랫폼과 소셜 미디어는 딥러닝을 통해 사용자 행동을 분석하고 개인화된 제품 추천과 광고를 제공합니다. - Automatic Machine Translation 자동 기계 번역
트랜스포머 모델과 같은 신경망은 규칙 기반 프로그래밍 없이도 높은 품질의 언어 번역을 가능하게 합니다. - Automatic Handwriting Generation 자동 필기 생성
딥러닝 모델은 다양한 스타일의 사람 필체를 합성할 수 있어, 접근성을 위한 핸드라이팅 생성에 활용됩니다. - Demographic & Election Predictions 인구 통계 및 선거 예측
딥러닝 알고리즘은 소셜 미디어, 여론 조사, 인구 통계 등 대규모 데이터를 분석하여 선거 결과를 예측하고 투표 패턴을 연구합니다. - Automatic Game Playing 자동 게임 플레이
딥러닝의 하위 분야인 강화 학습은 인공지능이 체스, 바둑, Dota 2와 같은 게임을 학습하고 인간을 능가하도록 지원합니다(예: AlphaGo, AlphaZero). - Language Translations 언어 번역
딥러닝은 구글 번역과 같은 앱에서 실시간 언어 번역을 가능하게 하여 다양한 언어 간 글로벌 커뮤니케이션을 지원합니다. - Pixel Restoration 픽셀 복원
딥러닝 기술은 손상되거나 저화질의 이미지를 복원하기 위해 손실되거나 훼손된 픽셀 데이터를 추론하여 시각적 품질을 개선합니다. - Photo Descriptions 사진 설명
이미지 캡셔닝 시스템은 딥러닝을 활용해 이미지에 대한 정확한 텍스트 설명을 생성하며, 시각 장애인을 돕거나 이미지 검색 엔진에 활용됩니다. - Deep Dreaming 딥 드림
딥드림은 딥러닝의 창의적인 응용분야로, 시각적 데이터를 기반으로 요소를 강화하고 과장하여 초현실적이고 꿈 같은 이미지를 생성합니다. 이러한 응용 사례들은 다양한 산업에서 딥러닝의 다재다능함과 혁신적 가능성을 보여줍니다
기본 용어 정리
- Artificial intelligence (~1980's)
인공지능 : 문제를 인식하고 해결하는 능력인 지능을 구현하는 기술
- Machine Learning (~2010's)
머신러닝 : 기계 스스로 학습하여 지능을 습득하는 기술을 말함.
- Deep Learning (2010's ~)
딥러닝 : 생체 신경망을 모방해서 만든 인공 신경망을 이용하여 복잡한 데이터 관계를 찾아내는 머신러닝 기법
DL Pros & Cons
Pros
- 함수 근사화를 상당히 잘 함
복잡한 비선형 문제를 학습할 수 있도록 설계되어 있다.
예: 이미지 인식, 음성 인식 등에서 특징이 복잡하게 얽혀 있는 데이터 구조를 정확히 모델링한다. - 특징 추출도 최적화로 해결
딥러닝은 원시 데이터를 입력받아 자동으로 의미 있는 패턴을 학습한다.
Convolutional Neural Networks(CNN)은 이미지에서 가장 중요한 시각적 특징(에지, 모양 등)을 알아서 학습한다. - 모델의 확정성이 뛰어남
빅데이터와 GPU/TPU와 같은 고성능 하드웨어가 결합하면 모델 크기와 성능을 확장할 수 있다. - 성능 자체가 뛰어남
딥러닝이 대규모의 데이터와 복잡한 문제를 처리하면서도 높은 수준의 예측 및 정확도를 제공한다.
Cons
- 비선형 최적화로 상당히 많은 파라미터를 찾아야 한다
수백만~수십억 개의 파라미터를 학습해야 하므로 훈련 과정이 복잡해지고 계산 비용이 증가한다.
높은 차원의 파라미터 공간에서 최적화가 이루어지기 때문에 **로컬 최적점(local minimum)**에 빠질 위험도 존재한다. - 훈련을 하는데 상당한 시간과 비용이 필요함.
복잡한 딥러닝 알고리즘(예: Transformer, GPT 모델)은 대규모의 데이터를 처리해야만 제대로 작동하는데, 이 과정에서 고성능 GPU/TPU와 대용량 데이터셋이 필요하다.
일반적인 CPU로 학습하려면 시간이 너무 오래 걸리고, 실제 기업에서는 클라우드 서비스(AWS, Google Cloud) 등으로 막대한 비용이 소모 - 최적의 모델을 하기 위해서는 더 시간이 필요함
하이퍼파라미터(학습률, 레이어 수, 뉴런 수 등)를 조정해야 하고, 데이터를 사전 처리하는 작업 또한 필요하다.
얼마나 많은 레이어와 노드를 사용해야 하는지, 어떤 활성화 함수(activation function)가 적합한지를 찾으려면 많은 시험 과정이 필요하다.
이론적으로는 강력하지만, 최적의 성능을 내는 모델을 설계하는 데는 오랜 시간이 걸릴 수 있다. - 해석이 거의 불가능하여서, 결과가 나오기 전까지 알기도 어려움
왜 어떤 특정한 결과를 제공했는지 명확히 설명하기 어려운 블랙박스 모델이다.
금융 분야나 의료 분야에서는 결과를 설명할 수 없는 모델은 신뢰성을 확보하기 어려우며, 정책적인 요구 사항을 충족시키지 못합니다. - 학습할 대용량의 데이터를 정제하고, 확보하는데 어려움.
모든 조직이 필요한 데이터를 확보할 수 있는 것은 아니며, 데이터 정제가 추가적으로 필수적이다.
데이터를 정제하고 라벨링하는 작업은 매우 시간과 비용이 많이 듭니다.
특히 데이터에 노이즈(잡음)가 많거나 라벨링이 제대로 되어 있지 않다면 모델 성능이 떨어질 가능성이 큽니다.
예: 자율주행차 개발을 위한 영상 데이터 수집과 라벨링 작업은 막대한 인력과 비용이 소모됩니다.
딥러닝의 구성 요소
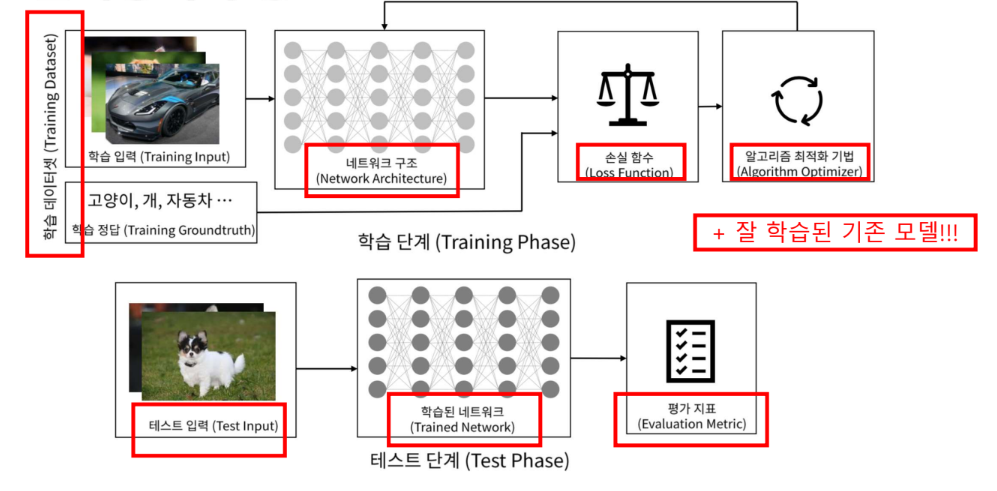
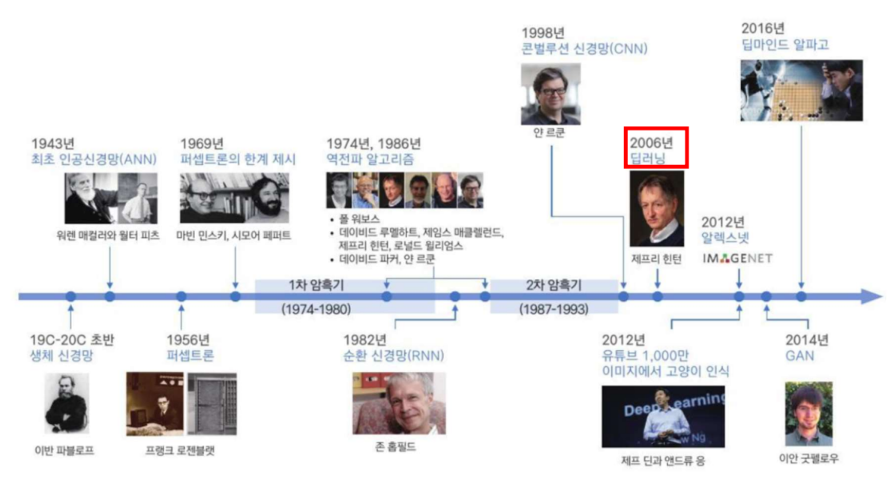
DL History
Hidden Layer : 은닉층
1. Dense Layer (밀집층)
- 다층 퍼셉트론(MLP) 신경망에서 가장 기본적인 구성 요소로, 입력 뉴런과 출력 뉴런이 모두 연결된 Fully Connected Layer의 한 형태
- 특징
- 모든 뉴런이 연결: 입력층의 모든 뉴런이 출력층의 모든 뉴런과 연결(완전 연결, Fully Connected).
- 가중치와 바이어스: 각 연결에는 가중치(Weight)가 할당되며, 뉴런에는 바이어스(Bias)가 더해져 신호를 조정
- 비선형성 추가: 활성화 함수(Activation Function)를 통해 비선형성을 추가함으로써 복잡한 관계를 학습 - 활용
- 주로 입력 데이터를 처리하거나 최종 출력을 생성하는 데 사용
- CNN, RNN 등의 모델에서는 마지막 출력 레이어에 Dense Layer를 사용해 최종 예측 값을 생성
2. Convolution Layer (합성곱층, CL)
- 주로 이미지 데이터를 처리하기 위해 설계된 레이어로, 입력 데이터에서 지역적인 특징(local feature)을 추출하는 데 초점을 맞춥니다.
- 작동 원리
1. 필터(Filter) 또는 커널(Kernel):
- 작은 크기의 행렬(예: 3×3, 5×5 등)을 정의하여 입력 이미지 전체를 슬라이딩하며 합성곱(Convolution) 연산을 수행
- 필터는 특정 패턴(가장자리를 감지하는 에지, 텍스처 등)을 탐지
2. 특징 맵(Feature Map) 생성:
- 필터를 통해 입력 이미지에서 특징(feature)을 감지한 결과가 특징 맵으로 저장
3. 활성화 함수 적용:
- ReLU(Rectified Linear Unit)와 같은 활성화 함수를 적용해 비선형성을 추가 - 특징
- 입력 데이터의 구조를 보존하면서 주요 특징을 감지
- 다수의 필터를 사용해 다양한 패턴(모양, 질감 등)을 동시에 학습할 수 있다.
- 파라미터 수를 줄임: Dense Layer와 달리, 일부만 연결되므로 학습해야 할 가중치 수가 적다.
3. Pooling Layer (풀링층, PL)
- Convolution Layer 뒤에 주로 사용되며, 특징 맵의 크기를 줄이고 계산 비용을 감소시키다. 동시에, 특징을 지역적으로 요약해 중요한 정보를 유지한다.
- 종류
1. Max Pooling (최대 풀링)
- 각 지역의 최대 값을 선택
- 특정 영역에서 가장 중요한 값(특징)을 보존하며, 노이즈를 억제
- 대부분의 CNN 모델에서 가장 널리 사용
2. Average Pooling (평균 풀링)
- 각 지역의 평균 값을 계산해 요약
- Max Pooling에 비해 부드러운 특징 표현에 유리 - 작동 원리
- 필터(예: 2×2, 3×3 등)를 사용해 입력 데이터의 특정 영역을 탐색하면서 각 영역의 값을 집약
- Stride(이동 간격)를 조정해 데이터 다운샘플링을 수행합니다(출력 크기 축소). - 특징
- 강건성(Robustness) 추가: 작은 변동(예: 이미지의 이동, 노이즈)에 대해 강건한 모델을 만듭니다.
- 계산 효율성: 데이터가 축소되기 때문에 다음 레이어로 전달되는 데이터 양이 줄어듭니다.
4. Fully Connected Layer (완전 연결층, FCL)
- 모든 노드가 완전히 연결된 Dense Layer의 한 형태로, Convolution 및 Pooling Layers로부터 추출된 중요한 특징들을 기반으로 최종 출력을 생성
- 특징
- 주로 CNN의 마지막 단계에서 사용
- Convolution과 Pooling을 거치면서 추출된 고차원 데이터를 1차원 벡터 형태로 받아들여 최종 예측을 생성
- 가중치가 많아 파라미터 학습이 복잡하지만, 모델의 최종 신경망 단계에서 중요한 역할을 수행 - 활용
- 이미지 분류: 이미지에서 추출된 특징을 받아 특정 클래스 레이블을 예측
- 회귀 문제: 연속적인 값을 예측
5. Flatten Layer (플래튼층)
- 다차원 데이터를 1차원 벡터로 변환하여 Fully Connected Layer에 전달하는 역할을 합니다.
- 필요성
- Convolution Layer와 Pooling Layer를 반복적으로 거치면 출력 데이터는 다차원 형태(예: 2D 매트릭스)로 표현됩니다.
- Fully Connected Layer는 1차원 벡터 형태의 데이터를 입력값으로 필요로 하므로, 다차원 데이터를 1차원으로 변환해야 합니다. - 작동 원리
- 입력 데이터를 1차원 배열로 변환하며, 데이터의 값을 변경하지 않습니다.
- 예:
- 원래 데이터: 5 *5 *3 (높이 × 너비 × 채널)
- Flatten 이후: 크기가 75인 1D 벡터
Convolutional Neural Network에서의 작동 흐름
CNN 모델에서는 Convolutional Layer와 Pooling Layer가 반복되어 특징을 추출하고, Flatten 및 Fully Connected Layer를 통해 최종 출력을 생성하는 구조로 동작한다.
1. Convolution Layer(CNN): 이미지 특징을 추출
2. Pooling Layer: 데이터의 크기를 줄여 계산 효율을 높임
3. Flatten Layer: 다차원 특징을 1차원 벡터로 변환
4. Fully Connected Layer: 모든 뉴런이 연결되어 최종 출력 생성
이처럼 각 레이어는 서로 역할을 분담하며, 빠르고 정확하게 데이터를 처리하고 학습한다.
CNN은 이미지, 영상 처리에 특히 강력한 성능을 발휘하며, 해당 계층 구조는 모델 설계의 핵심이 된다.
Convolution
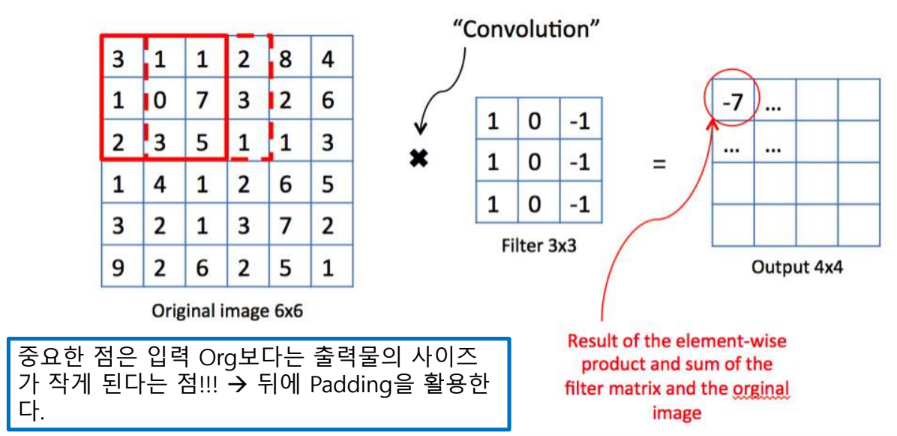
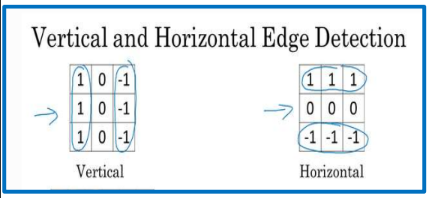
- Padding
- Conv를 하게 되면 OrgData보다 작아지게 되기 때문에 오리지널 이미지에 덧 데는 것
이미지를 더 크게 한 이후에 최종 결과가 원하는 본 이미지의 사이즈와 같게 하기 한다.

- Pooling Layer : Max pooling

- Pooling Layer : Average pooling
