ASAC 빅데이터 분석가 과정 12일차 - 2 (24.12.19)
07_xml_kobis
# XML의 특징
API에서 XML 양식으로 요청을 하고 받아서 하는 부분!!!
양식 : XML은 Tag 중심의 언어
<tag_name>해당tag값</tag_name>
<tag_name></tag_name>
<tag_name/>
# 참고) json : ~은 ~이다
# 참고) xml : 정보 시작합니다 ~ 정보 끝났습니다.
# csv와 xml의 차이
- csv -- excel
- xml -- html
- 데이터 전달에 있어서는 가볍게 핵심을 전달이 중요하 : csv, xml, json etc
# 필요한 패키지들
import pandas as pd
import urllib.request # 파이썬에서 http통신을 위한 패키지
from bs4 import BeautifulSoup
# xml/ html : tag 중심의 언어들 처리 : BeautifulSoup
# xml로 api 불러오기
Step1) xml 양식으로 요청을 50개 해보자 : 영화목록
# 기본 주소
url_p1 = "http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.xml"
# 필수 항목 : key
key = "e5b253a83f004635cd7fd625e9a0a839"
# 부가적으로 요청사항 : itemPerPage 사용해서 50개로 확장
url_p2 ="50"
# 위의 사항이 반영된 주소
url = url_p1 +"?key=" + key+"&itemPerPage="+url_p2
url
'http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.xml?key=e5b253a83f004635cd7fd625e9a0a839&itemPerPage=50'
Step2) http 통신으로 요청하고 받은 정보를 xml 패키지로 처리!!!
movie_page = urllib.request.urlopen( url)
# xml 양식을 처리하기 위해
# bs4 패키지 파싱 모듈 : "html.parser", "lxml.parser", etc
# api는 일반적인 사이즈이므로 별도의 파서 말고 일반적인 html로 사용
# 자세한 사항은 메뉴얼을 참조하자
soup = BeautifulSoup(movie_page, "html.parser" )
/usr/lib/python3.10/html/parser.py:170: XMLParsedAsHTMLWarning: It looks like you're parsing an XML document using an HTML parser. If this really is an HTML document (maybe it's XHTML?), you can ignore or filter this warning. If it's XML, you should know that using an XML parser will be more reliable. To parse this document as XML, make sure you have the lxml package installed, and pass the keyword argument `features="xml"` into the BeautifulSoup constructor. k = self.parse_starttag(i)
print(soup.prettify())
# 현실적으로는 다른 웹브라우저 탭에서 실제 보면서 하는게 편함
# 출력 생략
주의! 대소문자 틀어지는 경우들도 있다.
# JSON 패키지와 BS 패키지 차이
- JSON 패키지 : 파이썬의 기본 자료형을 변환한다.
- 정보 접근 : 정수인덱스, 키값
- 정보에 대한 접근할 때 바로는 못가고
거치는 과정을 통해 접근에 대한 경로 표현이 길어지게 된다. - BS 패키지 : tag 중심의 언어
- 직접 접근을 가능하게 한다.
- 파이썬의 기본 자료형이 아니다.
- find(찾을 테그명) : 여러 테그가 있을 경우, 맨 앞 1개
- find_all(찾을 테그명) : 테그에 해당하는 모든 정보를 다 찾아 준다.
: 리스트 [] (에러 처리 용이)
soup.find("movie")
<movie><moviecd>20233740</moviecd><movienm>제17회 안양여성인권영화제 단편섹션 3</movienm><movienmen></movienmen><prdtyear>2023</prdtyear><opendt></opendt><typenm>옴니버스</typenm><prdtstatnm>기타</prdtstatnm><nationalt>한국</nationalt><genrealt>드라마</genrealt><repnationnm>한국</repnationnm><repgenrenm>드라마</repgenrenm><directors></directors><companys></companys></movie>
soup.find("movies")
#테그가 없어 반응이 없다! (에러 처리에 불편)
soup.find_all("movie")[0]
<movie><moviecd>20233740</moviecd><movienm>제17회 안양여성인권영화제 단편섹션 3</movienm><movienmen></movienmen><prdtyear>2023</prdtyear><opendt></opendt><typenm>옴니버스</typenm><prdtstatnm>기타</prdtstatnm><nationalt>한국</nationalt><genrealt>드라마</genrealt><repnationnm>한국</repnationnm><repgenrenm>드라마</repgenrenm><directors></directors><companys></companys></movie>
soup.find_all("moviesss")
[]
soup.find_all("moviesss") == []
# 예외 처리에 find_all를 쓰면 편함 ( 개인취향껏 쓰기 )
True
# 실습
- 받은 영화 들 중에서 0번째 영화 정보 출력하기!
soup.find_all("movie")[0]
<movie><moviecd>20233740</moviecd><movienm>제17회 안양여성인권영화제 단편섹션 3</movienm><movienmen></movienmen><prdtyear>2023</prdtyear><opendt></opendt><typenm>옴니버스</typenm><prdtstatnm>기타</prdtstatnm><nationalt>한국</nationalt><genrealt>드라마</genrealt><repnationnm>한국</repnationnm><repgenrenm>드라마</repgenrenm><directors></directors><companys></companys></movie>
soup.find_all("movie")[0].find("moviecd")
<moviecd>20233740</moviecd>
soup.find_all("movie")[0].find("moviecd").text
'20233740'
soup.find_all("movie")[0].find("moviecd").get_text()
'20233740'
Q) 받은 영화의 정보가 몇 개인지
len(soup.find_all("movie"))
50
# 중요한 부분!
soup.find_all("moviecd")[0]
# 비추천 하는 방식!
# 수집하려는 정보의 단위 영화별로 다르다 (기본 정보 추출이 힘들다)
# 개별 영화에 대한 정보를 접근하고 거기서 필요한 정보 추출해야 한다.
# 데이터가 밀릴 수 있다.
<moviecd>20233740</moviecd>
# 체크 사항
Q) 1번 영화에 대해서 코드값을 출력해보기
Q) 1번 영화에 대해서 국문 제목을 출력해보기
Q) 1번 영화에 대해서 영문 제목이 있다면 출력해보기
Q) 1번 영화에 대해서 개봉 날짜가 출력해보기
Q) 1번 영화에 대해서 감독의 이름이 있다면, 1번 감독 이름 출력해보기
==> 개별 접근에 대해서 확인 후
Q) for문을 사용해서 받은 모든 영화들에 대해서 위의 정보들을 출력해보기
( 개별 영화에 대한 정보를 중심으로 처리해야 한다. )
soup.find_all("movie")[0]
<movie><moviecd>20233740</moviecd><movienm>제17회 안양여성인권영화제 단편섹션 3</movienm><movienmen></movienmen><prdtyear>2023</prdtyear><opendt></opendt><typenm>옴니버스</typenm><prdtstatnm>기타</prdtstatnm><nationalt>한국</nationalt><genrealt>드라마</genrealt><repnationnm>한국</repnationnm><repgenrenm>드라마</repgenrenm><directors></directors><companys></companys></movie>
soup.find_all("movie")[0].find("moviecd").text
'20233740'
soup.find_all("movie")[0].find("movienm").text
'제17회 안양여성인권영화제 단편섹션 3'
soup.find_all("movie")[0].find("movienmen").text
''
soup.find_all("movie")[0].find("opendt").text
''
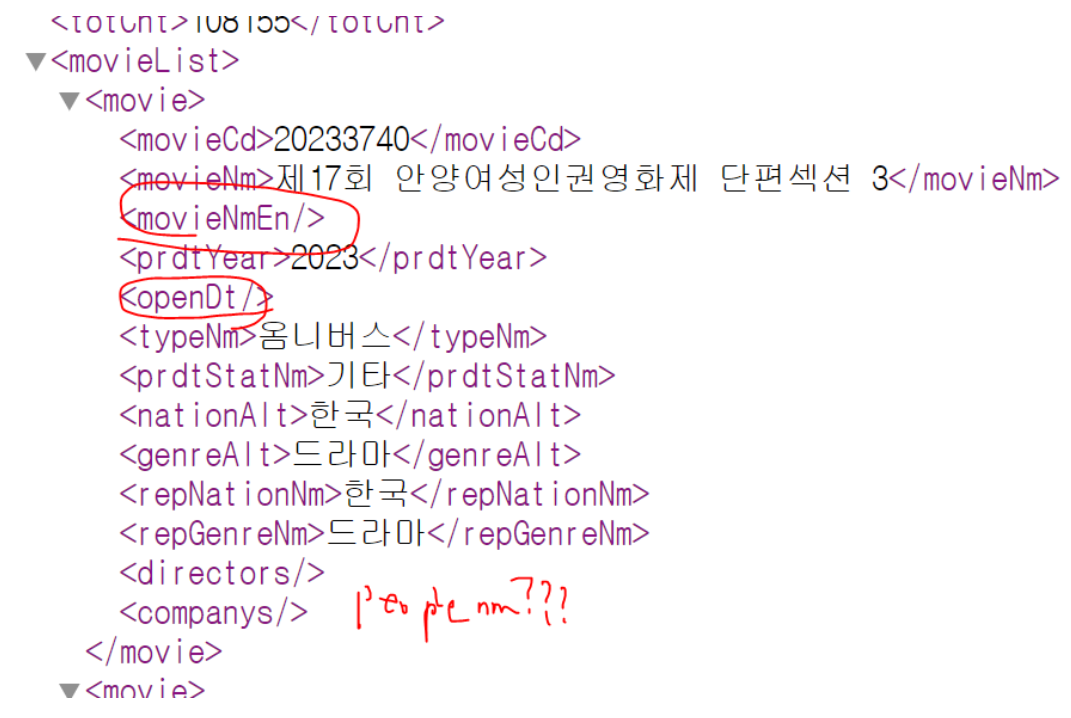
soup.find_all("movie")[0].find("peoplenm").text
# 아예 tag가 없다면 에러가 발생
AttributeError: 'NoneType' object has no attribute 'text'
if soup.find_all("movie")[0].find_all("peoplenm") != []:
soup.find_all("movie")[0].find("peoplenm").text
else:
print("감독이름X")
감독이름X
# ---> idx = 0
idx = 0
print( soup.find_all("movie")[idx].find("moviecd").text)
print(soup.find_all("movie")[idx].find("movienm").text)
print(soup.find_all("movie")[idx].find("movienmen").text)
print(soup.find_all("movie")[idx].find("opendt").text)
if soup.find_all("movie")[idx].find_all("peoplenm") != []:
print(soup.find_all("movie")[idx].find("peoplenm").text)
else:
print("감독이름X")
20233740
제17회 안양여성인권영화제 단편섹션 3
감독이름X
# for문으로 돌리기
tot_cnt = len( soup.find_all("movie"))
for idx in range(tot_cnt):
i_movie = soup.find_all("movie")[idx]
print( i_movie.find("moviecd").text)
print(i_movie.find("movienm").text)
print(i_movie.find("movienmen").text)
print(i_movie.find("opendt").text)
if i_movie.find_all("peoplenm") != []:
print(i_movie.find("peoplenm").text)
else:
print("감독이름X")
print("*"*50)
# 출력 생략
# Q) 위에 접근한 개별 영화에 대한 정보들을 DF에 담아보자
시도1) 어제 한 대로 리스트 안에 list로 처리!
시도2) 오늘 한 대로 리스트 안에 dict로 처리!
(앞에서 한 방법대로 1번에 하면 바로 DF으로 변경은 안 됨, json이랑 다름)
movie_list = []
for idx, data in enumerate(soup.find_all("movie")):
# data : 개별 영화 정보가 담긴 xml
# 개별영화정보 data를 기준으로 할 일을 하면 된다.
code = data.find("moviecd").text
name = data.find("movienm").text
ename = data.find("movienmen").text
date = data.find("opendt").text
if data.find_all("peoplenm") != []:
#dir_name = data.find_all("peoplenm")[0].text
dir_name = data.find("peoplenm").text
else:
dir_name = "X" # else 파트를 생략시, 데이터가 밀릴 수 있다.
movie_list.append( [code,name,ename,date, dir_name])
print("Done!!!")
Done!!!
pd.DataFrame(movie_list)
# DF으로 변경이 되기는 하지만 가로/세로에 내가 만든 인덱스가 없다
# 오직 태생적인 정수!
# 출력 생략
pd.DataFrame(movie_list,
# index=[~~~~] # movieCd 컬럼 가로 인덱스
columns = ["Code","Title","E-Title","openDay","Dir_name"]
)
# movie_list는 오로지 2차원 형식으로 값들만 정리가 된 것이다.
# 2D DF으로 생성할 때 가로/세로에 대한 틀이 필요하면
# index =[~~~], columns =[~~~] 으로 사용하면 된다.
# cf) df.rename(index={"A":"a"})
# df.rename(columns={"A":"a"})
# 출력 생략
# 개별 영화 정보를 dict 형태로 정리해서 []에 담기
movie_list = []
for idx, data in enumerate(soup.find_all("movie")):
# data : 개별 영화 정보가 담긴 xml
# *** 개별영화정보 data를 기준으로 할 일을 하면 됨!!! ***
i_dict ={"code":"", "title":"", "e-title":"",
"openday":"", "dir_name":"X"}
# --->
i_dict["code"] = data.find("moviecd").text
i_dict["title"] = data.find("movienm").text
i_dict["title"] = data.find("movienmen").text
i_dict["openday"] = data.find("opendt").text
if data.find_all("peoplenm") != []:
#dir_name = data.find_all("peoplenm")[0].text
i_dict["dir_name"] = data.find("peoplenm").text
#-----------------------------------
movie_list.append( i_dict )
print("Done!!!")
Done!!!
movie_list
# 출력 생략
pd.DataFrame(movie_list)
# 개별 영화 정보에 대한 dict의 키값을 컬럼명으로 올라가므로
# 처음에 할 때 컬럼명을 생각해서 코드를 하는 것이 중요하다.
# 출력 생략
# 개별 영화 정보 추가는 과제!!
*** 세미나 : github ==> 데이터 업로드 주의!!!!
--> 공개 설정 : 데이터 수집(개인, 조별 ml, dl)
: 데이터 csv/excel --> xxxx
문제가 생길 수 있다.
수집된 데이터는 절대로 공개된 부분에 업로드 하지 말기!!!!!
==> 모델은 괜찮음
==> 데이터 수집하는 코드는 고민
3~10개 정도만..
유출하지말기!!!