*** ML 하신 것들을 정리!!
=> 프로젝트 한 것들을 전체적으로 다 개인별로 파악!
=> 코드 정리!! (조원 공유) + 다른 조원분은 돌아가는지 체크!
=> 조별 공유 폴더
1. data 폴더 -> 정리
2. code 폴더 -> 정리
3. 기타 및 발표 자료 --> 참고 자료, 발표 자료, 기타 EDA 관련 자료
---------------------> 개인별로 포폴
개인별로 맞추어서 정리
3,4,5월 채용 시기 -> 미리 채용 준비해야한다.
기업 연계 프로젝트 할 때 같이 준비
(4~6월 지원해보면..) 알게 될 것!
DL : 4조
5 / 5 / 6 / 6
DL 스타일 ->
** 과거 모델은 : 포폴용으로 무쓸
** 최신 기술 : 논문 중심으로 조사
--> 논문 모델을 튜닝
1. 기본 내용과 논문 사이 갭
2. 논문 코드가 돌도록 밑작업 (삽질)
=> 시작하기 저까지 시간이 좀 걸림
3. 논문 결과는 100프로 신뢰하지 마세요
=> 본인 목적에 맞도록 모델의 최적화
++ 아이디어 + 실험 : 쉽게 논문 / 학회 제출이 가능!!
(최근에 DL 포지션도 학위 ---> 실적)
1조 : 김선규,박건,장길만,유민지,이승연
2조 : 조서영,하담,김희련,김나현,박태연
3조 : 이은우,이준석,강혜경,최지민,윤주노,백은진
4조 : 이승준,오수경,신가연,류찬솔,조혜원,이기찬
발표 : 3월 14일!!!! ( 변경 불가!!!! )
DL 예시
1.
모델 - the chosen one
모델 튜닝
2. 이미지 생성
배민 사이트에 음식을 올렸을 때
전문가가 찍은 것처럼 음식 사진을 바꿔주겠다.
**본인들의 프로젝트 목적
==> in/ out
(2D 정형데이터) ---- (1D 벡터)
DL (입력 출력에 대해서 고차원 비정형 데이터를)
==> 고차원 --> 고차원
(img + text) --> (img)
(text) ---> (img)
(text + text ) --> (img)
(text) --> (video) SORA
==> 고차원 데이터 같은 경우에 학습에 많은 시간이 든다.
GPT : 학습하는데 .. 미친듯이 + 시간!!
딥시크 ?? --> 가볍게 학습도 빨리해요
==> 코드나 패키지 안정화 X : 지금도 계속 바뀌고 있음
장점 : 내가 하는게 최초일 수 있음
코드를 GPT에 의존할 경우 힘들 수 있다.
최근 코드들은 더 애매할 수 있음
=> GPT는 참조정도만,, 에러는 직접 잡아야 한다.
메뉴얼 + 깃허브(requests) + 구글링 (잘 안 나올 수 있음)
----------------------------------------- ----------------------------------------- -----------------------------------------
** 출발은 무엇을 할까!!
==> in --> out 관점으로 생각을 하면 용이함
최근 연구들은 뭐가 있는지 문헌 조사!!
+++ 필요한 것들은 그때그때 채워야 한다.
----------------------------------------- ----------------------------------------- -----------------------------------------
석사 FM
기본 내용 공부
특정 주제에 대한 논문 히스토리들을 쭉 공부
+ 코드는 모르고
+ 최근 연구까지 가면 과정이 끝남
+ 본인 연구 주제 + 실험 + 결과
본인 연구 주제 => 최근 연구 => 과거에 뭘 했는지 (역추적) //결과가 중요하기 때문에 조사가 필수적
Deep Learning pdf
20 Deep Learning applications
- Self Driving Cars 자율 주행차
딥러닝은 자율주행차의 핵심 기술로, 신경망과 컴퓨터 비전을 활용해 객체 감지, 도로 주행, 교통 표지판 인식, 장애물 회피 등을 가능하게 합니다. - Entertainment 엔터테인먼트
넷플릭스, 스포티파이, 유튜브와 같은 플랫폼은 딥러닝 기반 추천 시스템을 활용해 사용자의 시청/청취 패턴을 분석하고 개인화된 콘텐츠를 제공합니다. - Visual Recognition 시각적 인식
합성곱 신경망(CNN)과 같은 딥러닝 모델은 이미지 및 비디오에서 객체를 식별하고 분류하는 데 뛰어나며, 이를 보안, 의료, 소매업 등 다양한 산업에 적용할 수 있습니다. - Virtual Assistants 가상 비서
시리, 구글 어시스턴트, 알렉사와 같은 가상 비서는 딥러닝을 활용해 자연어 명령을 처리하고, 음성 인식 기능을 개선하며, 정확한 응답을 제공합니다. - Fraud Detection 사기 탐지
딥러닝 알고리즘은 금융 거래의 패턴과 비정상적인 점을 분석해 은행 및 전자 상거래에서 사기를 탐지하고 방지하는 데 기여합니다. - Natural Language Processing 자연어(NLP) 처리
딥러닝은 감정 분석, 언어 생성, 번역, 질문 응답, 챗봇 기능 등 자연어 처리 작업을 지원하며, BERT와 GPT와 같은 모델이 이를 주도합니다. - News Aggregation and Fraud News Detection 뉴스 수집 및 가짜 뉴스 탐지
딥러닝 알고리즘은 뉴스 기사를 주제별로 클러스터링하고, 작성 패턴과 출처의 신뢰성을 분석하여 가짜 뉴스를 탐지합니다. - Detecting Developmental Delay in Children 아동 발달 지연 탐지
의료 연구자들은 딥러닝 모델을 활용해 아동의 발달 패턴을 분석하고 자폐증, ADHD 및 기타 발달 장애의 초기 징후를 감지합니다. - Colourisation of Black and White images 흑백 이미지 컬러화
고급 딥러닝 모델은 흑백 사진이나 비디오를 자동으로 컬러화하며, 역사적 이미지를 현실감 있게 복원합니다. - Adding sounds to silent movies 무성영화에 소리 추가
딥러닝 기술을 활용하면 시각적 콘텐츠를 기반으로 주변음을 인식하고 시뮬레이션하여 무성영화에 오디오를 재현할 수 있습니다. - Healthcare 헬스케어
딥러닝은 암 진단, 의료 영상에서의 이상 탐지, 환자 예후 예측, 로봇 수술 시스템 등에 활용되어 의료 분야를 혁신합니다. - Personalisations 개인화
전자상거래 플랫폼과 소셜 미디어는 딥러닝을 통해 사용자 행동을 분석하고 개인화된 제품 추천과 광고를 제공합니다. - Automatic Machine Translation 자동 기계 번역
트랜스포머 모델과 같은 신경망은 규칙 기반 프로그래밍 없이도 높은 품질의 언어 번역을 가능하게 합니다. - Automatic Handwriting Generation 자동 필기 생성
딥러닝 모델은 다양한 스타일의 사람 필체를 합성할 수 있어, 접근성을 위한 핸드라이팅 생성에 활용됩니다. - Demographic & Election Predictions 인구 통계 및 선거 예측
딥러닝 알고리즘은 소셜 미디어, 여론 조사, 인구 통계 등 대규모 데이터를 분석하여 선거 결과를 예측하고 투표 패턴을 연구합니다. - Automatic Game Playing 자동 게임 플레이
딥러닝의 하위 분야인 강화 학습은 인공지능이 체스, 바둑, Dota 2와 같은 게임을 학습하고 인간을 능가하도록 지원합니다(예: AlphaGo, AlphaZero). - Language Translations 언어 번역
딥러닝은 구글 번역과 같은 앱에서 실시간 언어 번역을 가능하게 하여 다양한 언어 간 글로벌 커뮤니케이션을 지원합니다. - Pixel Restoration 픽셀 복원
딥러닝 기술은 손상되거나 저화질의 이미지를 복원하기 위해 손실되거나 훼손된 픽셀 데이터를 추론하여 시각적 품질을 개선합니다. - Photo Descriptions 사진 설명
이미지 캡셔닝 시스템은 딥러닝을 활용해 이미지에 대한 정확한 텍스트 설명을 생성하며, 시각 장애인을 돕거나 이미지 검색 엔진에 활용됩니다. - Deep Dreaming 딥 드
딥드림은 딥러닝의 창의적인 응용분야로, 시각적 데이터를 기반으로 요소를 강화하고 과장하여 초현실적이고 꿈 같은 이미지를 생성합니다. 이러한 응용 사례들은 다양한 산업에서 딥러닝의 다재다능함과 혁신적 가능성을 보여줍니다!
Self-Driving
Adding Sounds to Silent Movies
Synthesizing Obama: Learning Lip Sync from Audio
How To Colorize B&W Videos Using Deep Learning
Pixel Restoration
Describing photos
주된 응용 분야
- Computer Vision
- Patteren Recognition
- Game / Robot / Self Driving
- Souds / Art
=> ROBOT
기본 용어 정리
- Artificial intelligence (~1980's)
인공지능 : 문제를 인식하고 해결하는 능력인 지능을 구현하는 기술
- Machine Learning (~2010's)
머신러닝 : 기계 스스로 학습하여 지능을 습득하는 기술을 말함.
- Deep Learning (2010's ~)
딥러닝 : 생체 신경망을 모방해서 만든 인공 신경망을 이용하여 복잡한 데이터 관계를 찾아내는 머신러닝 기법
ML vs DL
- 전통적인 ML의 알고리즘은 특정한 문제에 맞게 알고리즘이 특화되어 발전
을 함. - DL은 데이터의 복잡한 관계를 잘 표현하기 때문에 다양한 문제에 보편적으
로 적용할 수 있음! - 작은 규모의 정형적인 문제의 경우에는 기존의 ML의 방법으로 접근을 하고,
기존의 ML로 풀기 어려운 것들의 규모가 크거나 복잡한 경우에는 DL로 접
근할 수 있는지 파악할 것! - DL은 문제의 복잡도에 맞춰서 모델을 쉽게 확장할 수 있으며, 모델이 커지
면 복잡한 관계를 표현할 수 있는 능력도 증가함.

DL Pros & Cons
Pros
- 함수 근사화를 상당히 잘 함
복잡한 비선형 문제를 학습할 수 있도록 설계되어 있다.
예: 이미지 인식, 음성 인식 등에서 특징이 복잡하게 얽혀 있는 데이터 구조를 정확히 모델링한다. - 특징 추출도 최적화로 해결
딥러닝은 원시 데이터를 입력받아 자동으로 의미 있는 패턴을 학습한다.
Convolutional Neural Networks(CNN)은 이미지에서 가장 중요한 시각적 특징(에지, 모양 등)을 알아서 학습한다. - 모델의 확정성이 뛰어남
빅데이터와 GPU/TPU와 같은 고성능 하드웨어가 결합하면 모델 크기와 성능을 확장할 수 있다. - 성능 자체가 뛰어남
딥러닝이 대규모의 데이터와 복잡한 문제를 처리하면서도 높은 수준의 예측 및 정확도를 제공한다.
Cons
- 비선형 최적화로 상당히 많은 파라미터를 찾아야 한다
수백만~수십억 개의 파라미터를 학습해야 하므로 훈련 과정이 복잡해지고 계산 비용이 증가한다.
높은 차원의 파라미터 공간에서 최적화가 이루어지기 때문에 **로컬 최적점(local minimum)**에 빠질 위험도 존재한다. - 훈련을 하는데 상당한 시간과 비용이 필요함.
복잡한 딥러닝 알고리즘(예: Transformer, GPT 모델)은 대규모의 데이터를 처리해야만 제대로 작동하는데, 이 과정에서 고성능 GPU/TPU와 대용량 데이터셋이 필요하다.
일반적인 CPU로 학습하려면 시간이 너무 오래 걸리고, 실제 기업에서는 클라우드 서비스(AWS, Google Cloud) 등으로 막대한 비용이 소모 - 최적의 모델을 하기 위해서는 더 시간이 필요함
하이퍼파라미터(학습률, 레이어 수, 뉴런 수 등)를 조정해야 하고, 데이터를 사전 처리하는 작업 또한 필요하다.
얼마나 많은 레이어와 노드를 사용해야 하는지, 어떤 활성화 함수(activation function)가 적합한지를 찾으려면 많은 시험 과정이 필요하다.
이론적으로는 강력하지만, 최적의 성능을 내는 모델을 설계하는 데는 오랜 시간이 걸릴 수 있다. - 해석이 거의 불가능하여서, 결과가 나오기 전까지 알기도 어려움
왜 어떤 특정한 결과를 제공했는지 명확히 설명하기 어려운 블랙박스 모델이다.
금융 분야나 의료 분야에서는 결과를 설명할 수 없는 모델은 신뢰성을 확보하기 어려우며, 정책적인 요구 사항을 충족시키지 못합니다. - 학습할 대용량의 데이터를 정제하고, 확보하는데 어려움.
모든 조직이 필요한 데이터를 확보할 수 있는 것은 아니며, 데이터 정제가 추가적으로 필수적이다.
데이터를 정제하고 라벨링하는 작업은 매우 시간과 비용이 많이 듭니다.
특히 데이터에 노이즈(잡음)가 많거나 라벨링이 제대로 되어 있지 않다면 모델 성능이 떨어질 가능성이 큽니다.
예: 자율주행차 개발을 위한 영상 데이터 수집과 라벨링 작업은 막대한 인력과 비용이 소모됩니다.
ML --> Feature : 기존과 다른 어떤 특징을 사용해서 성능이 개선되었는가
DL --> 어떤 모델/ 어떤 구조/ 어떤 데이터로 학습 --> 성능이 개선되었는가
영상쪽은 성능!
==> 전공, 일 경력이 의료!
(대학병원 : 교수들 -> 논문!)
: 프로젝트를 할 사람들(계약 : 엔지니어 + 데이터 핸들링 + 모델링)
+ 학위하면서 일하기
DL 구성 요소 -간략히 소개-
딥러닝의 구성 요소

- 학습 단계(Training Phase)
학습 데이터(Training Dataset) -> 네트워크 구조(Network Architecture) -> 손실 함수(Loss Function) -> 알고리즘 최적화 기법(Algorithm Optimizer) - 테스트 단계(Test Phase)
테스트 입력(Test input) -> 학습된 네트워크(Trained Network) -> 평가 지표(Evaluation Metric)
DL History

필요 개념 사전 체크
생물학의 뉴런 vs 인공신경망의 퍼셉트론
생물학적 뉴런과 인공 신경망의 퍼셉트론은 신호 처리라는 본질적인 유사성을 가지지만, 작동 방식과 구조의 세부 사항에서 차이가 있다.
생물학적 뉴런은 실제 뇌에서 신호를 처리하는 물리적 시스템이고, 퍼셉트론은 이를 수학적, 계산적으로 모델링한 것이다.
딥러닝은 이러한 생물학적 뉴런의 작동 원리에 기반하면서도 컴퓨터 처리에 최적화하여 발전한 기술로, 인류의 학습 능력을 흉내 내고자 하는 인공지능의 중요한 도구다.
Layer
- Input Layer : 입력층
- 입력 뉴런들로 구성된 층 - Output Layer : 출력층
- 출력을 만들어 내는 층 - Hidden Layer : 은닉층
Hidden Layer : 은닉층
- Dense Layer : 다층 퍼셉트론 신경망에서 사용되는 레이어
-> 입력/ 출력 모두 연결 - CL : Convolution Layer
- 이미지가 가진 특성이 고려된 신경망
- 입력 이미지를 특정 Filter, Kernel을 이용하여 탐색하면서 이미지의 특징을 추출하고, 추출한 특징들을 Feature Map으로 생성 - PL : Pooling Layer
- 주로 MaxPoolingLayer를 CNN 모델에서 사용
-> 주로 이미지에서는 CL층과 PL층은 같이 사용됨 - FCL : Fully Connected Layer
- 연결 가능한 것을 모두 연결 - Flatten Layer : Convolution Layer이나 Max Pooling Layer를 반복적으로 거치면 주요 특징만 추출되고 추출된 주요 특징은 전결합층에 전달되어 학습된다.
-> 전결합층에 전달하기 위해서 1차원의 자료로 바꿔주는데 사용되는 Layer
Convolution
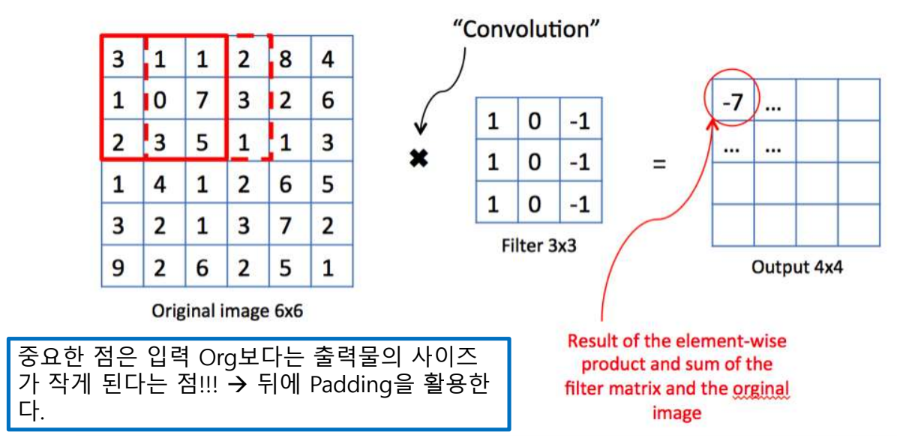
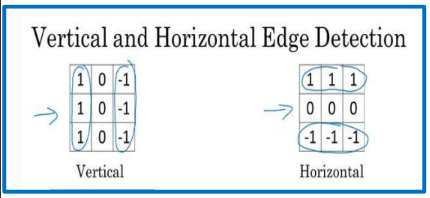
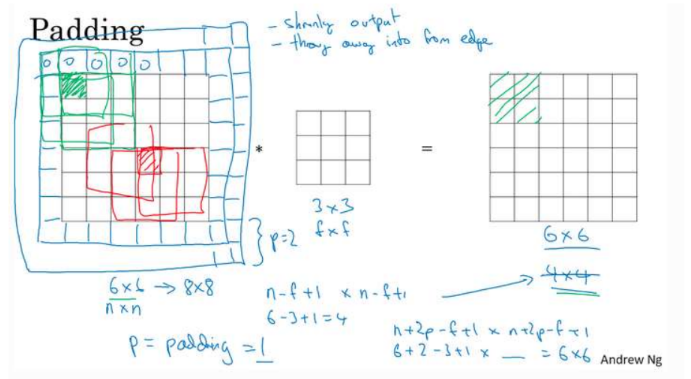
- Padding
- Conv를 하게 되면 OrgData보다 작아지게 되기 때문에 오리지널 이미지에 덧 데는 것
이미지를 더 크게 한 이후에 최종 결과가 원하는 본 이미지의 사이즈와 같게 하기 한다.
- Pooling Layer : Max pooling
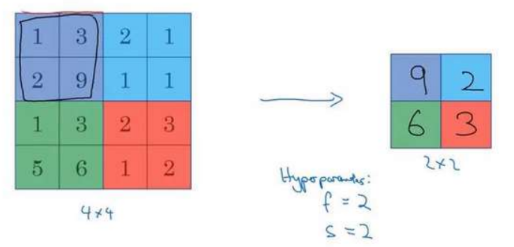
- Pooling Layer : Average pooling
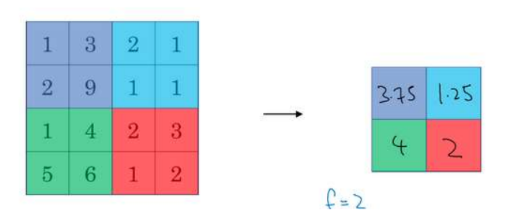
기억할 부분!!
- 합성함수
- 딥러닝 모델은 여러 층의 함수를 합성해서 복잡한 문제를 해결한다. - 선형결합
- 각 뉴런은 입력 데이터를 선형적으로 조합하여 계산을 수행한다. - input/output 구조
- 모델은 입력층, 은닉층, 출력층으로 구성되며, 데이터는 전방 전달을 통해 처리된다. - 비선형성
- 활성화 함수를 통해 비선형성을 도입해 복잡한 데이터 표현과 학습이 가능해진다.
딥러닝(Deep Learning, DL)
- 데이터에서 패턴을 학습하고 복잡한 문제를 해결하기 위해 여러 층(layer)으로 구성된 인공 신경망(ANN)을 활용
1. 합성함수 (Composite Function)
- 딥러닝 모델은 수학적으로 합성함수(Composite Function)로 표현된다.
(합성함수란, 여러 개의 함수를 결합해 하나의 함수로 구성하는 것을 의미)
딥러닝에서는 하나의 층(layer)을 하나의 함수로 간주하며, 여러 층을 쌓아 올리면 다음과 같은 형태의 합성함수가 만들어진다.


작동 원리
- 입력 데이터 x가 첫 번째 함수 f1에 전달되고, 그 출력을 f2에 전달하는 방식으로 계산이 순차적으로 진행된다.
- 이를 전방 전달(Forward Propagation)이라고 하며, 딥러닝의 기본적인 정보 흐름이다.
- 합성함수 구조를 통해 딥러닝 모델은 간단한 입력 값을 복잡한 형태로 변환하고, 더 높은 수준의 추상적 표현을 학습할 수 있다.
2. 선형결합 (Linear Combination)
- 딥러닝의 기본 계산 단위는 각 뉴런(Neuron)에서 입력 데이터들이 선형결합(Linear Combination)으로 계산된다.

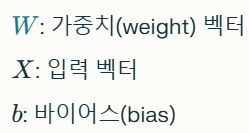
1. 가중치 W: 입력 데이터 X에 곱해지는 값으로, 입력 데이터의 중요도를 조절한다.
- 예: 이미지 데이터에서 특정 픽셀의 중요도를 설정.
2. 바이어스 b: 선형결합의 결과를 조정하기 위해 더해지는 상수다.
- 바이어스는 데이터를 더 잘 표현할 수 있도록 모델의 유연성을 증가시킨다.
3. 선형결합의 역할:
- 입력 데이터 X의 값과 가중치를 곱하고 합산해 뉴런의 출력을 계산한다.
- 이 과정은 사실 딥러닝에서 "입력 신호를 하나의 값으로 요약하는 과정"입니다.
3. 딥러닝의 Input/Output 구조
입력층(Input Layer)
- 데이터가 딥러닝 모델로 들어오는 최초의 층이다.
- 입력 뉴런의 개수는 데이터의 차원(특징 수)과 동일하다.
- 예: 이미지(28×28 픽셀) → 입력 뉴런 개수 = 784개
- 예: 범죄 데이터(연령, 지역, 시간 등 5개의 특징) → 입력 뉴런 개수 = 5개
은닉층(Hidden Layer)
- 입력 데이터를 처리하고, 다음 층으로 전달할 중요한 패턴과 특징을 학습한다.
- 은닉층은 입력층과 출력층 사이에 위치하며, 일반적으로 여러 계층을 사용한다.
- 각 은닉층은 가중치와 바이어스 값을 사용해 데이터 변환을 수행한다.
출력층(Output Layer)
- 모델의 최종 결과를 출력한다.
- 출력 뉴런의 개수는 문제 유형에 따라 다르다.
- 분류 문제: 클래스 수와 동일한 출력 뉴런 (예: 손글씨 숫자 분류 → 10개의 출력 뉴런)
- 회귀 문제: 1개의 출력 뉴런 (예: 연속적인 값 예측)
4. 비선형성 (Non-Linearity)
선형의 한계
- 선형결합은 단순히 입력 데이터를 "직선"으로 나눌 수 있는 문제만 해결할 수 있다.
- 선형 모델은 복잡한 데이터나 비선형적 관계(곡선 형태)를 학습하기 어렵다.
비선형성의 도입
- 딥러닝에서 활성화 함수(Activation Function)를 통해 비선형성을 추가한다.
- 비선형성을 도입하면 모델이 단순한 입력과 출력의 관계를 넘어서 복잡한 패턴과 데이터 간의 상호작용을 학습할 수 있다.
활성화 함수의 역할
- 선형결합 결과 z = W*X + b에 비선형 처리를 적용하여 출력 값을 조정한다
a = Activation(z)
- 활성화 함수는 뉴런의 출력 값을 비선형 형태로 변환하여 모델이 복잡한 문제를 해결할 수 있도록 돕는다.
주요 활성화 함수
1. ReLU (Rectified Linear Unit)
- f(z) = max(0, z)
- 음수는 0으로, 양수는 그대로 전달.
- 계산이 간단하고, 딥러닝 모델에서 가장 널리 사용됨.
2. Sigmoid

- 출력 값을 0~1 범위로 압축.
- 주로 이진 분류에서 사용.
3. Tanh (Hyperbolic Tangent)
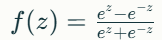
- 출력 값을 -1에서 1 사이로 매핑.
- Sigmoid보다 중심이 0에 가까워 학습이 더 쉬운 경우가 있음.
4. Softmax

- 출력 뉴런의 값들을 확률처럼 해석할 수 있도록 변환.
- 다중 클래스 분류에서 사용.
딥러닝의 합성함수, 선형결합, 비선형성의 관계
1. 입력 데이터 X는 각 뉴런에서 선형결합(W·X + b)을 통해 변환된다.
2. 선형결합의 결과는 활성화 함수를 통해 비선형성을 추가하여 더 복잡한 패턴을 학습할 수 있게 된다.
3. 이러한 과정을 여러 층(layer)에서 반복함으로써, 각각의 층은 특정 특징(feature)을 추출하여 합성함수로 표현된다.
4. 모델의 전체 구조는 입력층에서 출력층까지 연결된 합성함수로 나타나며, 이를 통해 단순한 입력 데이터를 복잡한 고차원 표현으로 변환한다.
DL은 무조건 이미지를 사용하는 순간 무조건 GPU가 있어야 함
=> colab에서 진행 (기본적인 모델들)
조별 플젝 : colab 가능할 수도 있고, 클라우드에서 해야할 수 있음
가장 기본 : Python
EDA : 전처리 정도 + 데이터 핸들링에 코드화 => pandas
ML : scikit-learn + pandas + 시각화 + optuna etc
DL :
TensorFlow (+ Keras) -> google
#초창기에 회사들에서 많이 사용했음
1.x -> 2.x 완전히 다른 친구
#전통적인 모델들은 Keras를 이용하는게 편함
주로 : 조립방식 + 함수방식 + 클래스
최근 연구되는 모델 + 논문 + github [PyTorch] -> Facebook
#버전 이슈 (os버전, os종류, cuda 버전, etc)
+ 세팅(python + anaconda 버전 + 기타 패키지까지)
+ 클래스 중심으로 코드를 작성해야 함
처음 기본적인 모델들은 주로 TF 중에서도 keras 중심으로 하겠다.
Tensorflow
colab에서는 이미 설치되어 있음
자기들꺼여서.. pytorch 설치해야 함!
import tensorflow as tf
tf.__version__
colab에서 갑자기 tensorflow 버전을 업그레이드할 때가 있다.
데이터를 표현 + 차원을 중심으로 => Tensor
python : list / tuple
numpy : array (차언, 모양, 벡터연산) --> np.array()
<--> pytorch, tf 모두 다 기본이 되는 자료형이 numpy의 array
TF : tensor (고차원에 대한 연산, 차원 + 모양 + 연산 + GPU)
pytorch : torch.
예) 쌩 파이썬의 리스트를 TF의 Tensor로 형변환
a=[1,2,3]
a
[1,2,3]
import numpy as np
arr = np.array(a)
arr
array([1,2,3])
arr.ndim
1
arr.shape
(3,)
t_1 = tf.constant([1,2,3])
t_1
t_1.shape
t_1.dtype
t_2 = tf.constant([1,2,3],[4,5,6])
t_2
[
[1,2,3],
[4,5,6]
]
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 44일차 (25.02.12) (0) | 2025.02.12 |
|---|---|
| ASAC 빅데이터 분석가 과정 43일차 (25.02.11) (0) | 2025.02.11 |
| ASAC 빅데이터 분석가 과정 41일차 (25.02.07) (0) | 2025.02.07 |
| ASAC 빅데이터 분석가 과정 40일차 (25.02.06) (0) | 2025.02.06 |
| ASAC 빅데이터 분석가 과정 39일차 (25.02.05) (1) | 2025.02.05 |