8_dl
1_code
6_yolo
yolo : 이미지 쪽 관련된 모델들 모아둔 것
--> 예전부터 계속 버전업!
--> 가벼운 모델~ 무거운 모델
--> 이미지 쪽에서 여러 task 모델
: 성능이 제일 best는 아님
사용하기가 유용하기에!! 튜닝!!
- yolo T4이상은 사용을 해야 할 듯!!!
- # YOLO : (이미지 관련 모델) 패키지 & 이미지 관련 task
# : Facebook --> SAM : Segmenent
# ==> 영상쪽에서 종종 yolo 모델을 사용할 떄 : Fast
# 가성비 쪽이여서 주로 활용을 했었습니다...
# 최근에는 test 용으로 확인할 때 종종 사용하는거 같습니다...
# Task : 이미지에 대한 분류 : 개/고양이 --> 개 or 고양이 중 뭐냐?
# 검출 : 개가 있는지 체크해줘!!! ---> 있다면,,어디에 있냐?
# segmentation : 대상 물체의 pixel 어디에 있는지(영역을 정확!!)
# ...
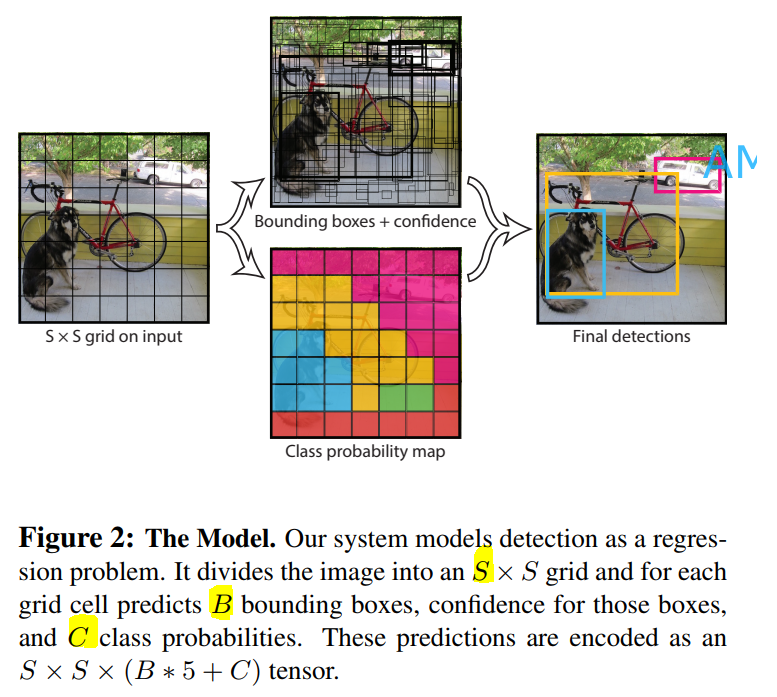

- # YOLO 초기 논문상 기호
# S : 입력 이미지에 대한 격자 정보 --> 이미지를 S 크기로 나눈 크기
# B : 1개 격자 속에 있는 박의 수
# ===> 1개 box 중심으로 정보 : P(확률), 박스에 대한 정보
# P(확률), x,y,w,h ==> 기준좌표 + W/h
# ( 단, 데이터, 사용하는 모델마다 이 "기준"이 다를 수 있음!!)
# ==> 하실 기준에 대해서 정확하게 파악을 하고 진행을 해야함!!
# C : 찾고자 하는 class의 정보!!!
# ===> ver1 논문상 : S= 7, B =2, C =20
# 최종 출력 : S * S * (B*5+C) = 7 * 7* 30
# ===> 이 모델이 주는 정보를 정확하게 처리하는 부분이 중요!!!! - # YOLO 학습을 하기 위해서는 필요한 파일!!!
# 1. 모델별로 사전 학습된 파일 : weight
# 2. 모델을 돌리는 환경 설정 관련!!!
# 3. 기존 학습된 라벨에 대한 정보!!!
# : ver1 --> ImageNet, ver3 --> COCOnet(80종 검출!!)
# --> 사용하는 버전에 맞는 모델 정보들을 다운로드!
# yolo3
!gdown 11NDUoHzKWRWEtaJNPX7srk6SQslQQ32Z
!gdown 1TY0iP3jLMB0jXHeQQ2Lgh5ZI1SGpabkI
!gdown 18Y8siRgCy2ZeChM_V4E-DLi0VKxHkg8G
- # 기본적인 데이터셋으로 학습을 해서 배포!!!
# ==> 일반적인 모델!!! 나만의 특수성이 없음!!! --> Tunning!!!!2
# LoRA, ..,,, : 모델 weight 다 학습하기에는 힘들어요;;;
# 조금만 학습해서,,,목적에 맞도록 튜닝을 하자!!!!
# ==> 80개는 어느 정도 하는데,,,내가 하려는 대상/탐지하려는 대상이
# 학습한 80개에 없으면 어쩔????
# : 사용자가 본인 목적에 맞도록 재학습을 할 수 있도록 배포!!#!
# : /// 여러 분들이 주로 하시는 프로젝트의 방향!!!!
- # https://www.kaggle.com/competitions/global-wheat-detection/data
# 대회 : kaggle
# : 벼 이삭에 대한 객체 탐지!!!!( 분류 X )
# ===> 공정 쪽에서 사용이 되는 이미지 분석/ 이미지 처리 기본!!!
# but) 기존에 있는 모델을 바탕으로 내가 다시 학습을 할 수 있고!!!
# 이미 어느 정도 이런 탐지를 잘 하는 모델 yolo v3 기준으로 튜닝!!!
# 내 목적에 맞는 나의 데이터로 튜닝을 해보자!!!!
# ===> 기존 coco의 80개 검출은 알빠노,,,내가 원하는 이삭만 잘 찾자!!!!
# 평가 : IoU ---> 이삭에 대한 박스를 최대한 잘 타이트하게 찾아보세요!!!
# ***** Box : Dectecion 에서 기준을 정확하게 체크 하고 진행을 해야 함!!! ****
# yolo v3~~v5 : 기준이 무엇이냐 체크!!!!
# ===> 논문 상에서는 가운데 좌표x,y, w,h ( 중심 좌표 기준) ** 약간 yolo 특이스타일;;;
# kaggle /coco ==> x,y,w,h( x,y 박스 좌측 상단!!!!) *** 일반 스타일
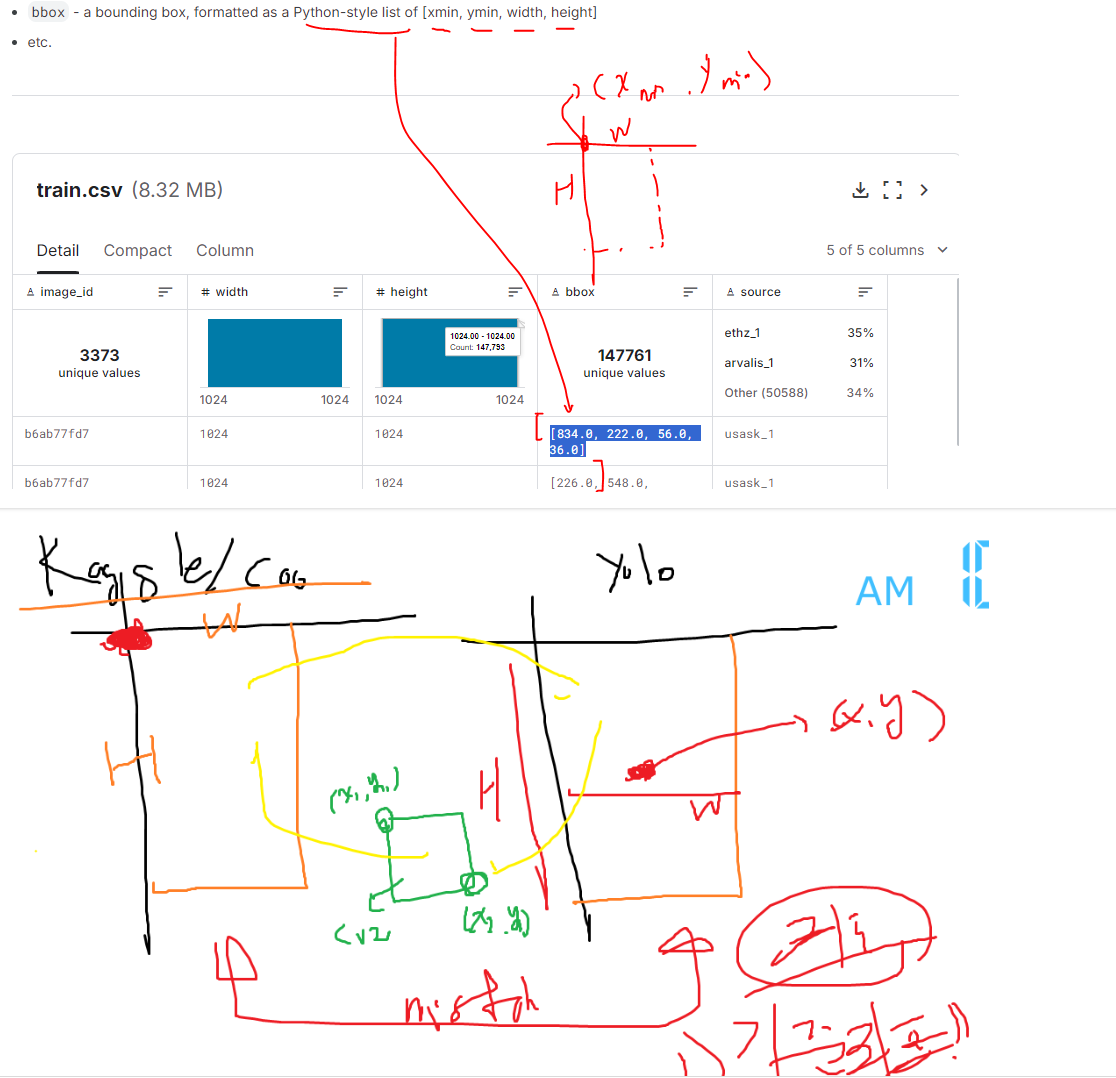
- # 참고) colab + 구글 드라이브 환경상!!!!! ( 실제 현업 가시면 이런 고민 XXX )
# ---> colab과 구글 드라이브 : 파일이 많으면,,,지연이 심함!!!!!
# ---> 구글 드라이브에 zip 압축해서 올리시고, 공유 설정,
# colab 그 파일을 다운로드 받아서, colab에서 압축을 직접 풀어서!!!
# ---> colab서버에 파일들이 존재하게 됨!!!(단, 전체 용량이 200기가 보다 작아야)
# kaggle에 있는 데이터 셋을 구글드라이브에 올리고,,다운
!gdown 1iXn1p_bW4JO9qL3iSkXNFh7ngqs-gkhA
# 압축을 코드로 풀어야 함!!!
# ==> 간단하게 하는 방법 중 하나가 리눅스 명령어로 푸는!!
# ==> 어떤 파일을(-qq),,,어디에 풀지(-d)
!unzip -qq "/content/global-wheat-detection.zip" -d "/content/data/"
- # kaggle에서 본 대로 데이터셋이 data 폴더 안에 존재하게 됨!!!
# train 폴더 안에 이미지들...
# test 폴더 안에 이미지들...
# data 폴더 안에...샘플 제출 양식
# data 폴더 안에,,,train 에 대한 박스 정보 정답지!!!
# 기본적인 데이터를 처리!!
# ==> 박스에 대한 정답 : train.csv 파일
# ==> val에 대한 정보들이 없음!!!!
import pandas as pd
import numpy as np
# 받은 train 폴더에 대한 이미지들을 원하는 폴더구조 변경!!!
# ===> 파일에 대한 이동/ 복사 : 코드화
# colab에서 이런 부분을 담당할 떄 shutil
import shutil as sh
# + opt) val에 대해서 없다면,,,저희가 직접 폴더를 생성....
# ===> train 품종에 대한 학습 데이터가 다르면,,,
# ===> 원본 비율을 유지하면서,,,val을 하는게 좋겠다!!!
from sklearn.model_selection import StratifiedKFold
df = pd.read_csv("/content/data/train.csv")
df.head()

df.at[0, "bbox"]
'[834.0, 222.0, 56.0, 36.0]'
type( df.at[0, "bbox"] )
str
df.at[0, "bbox"][1:-1]
'834.0, 222.0, 56.0, 36.0'
# ===> 박스 좌표에 대한 문자열 : 리스트 형 변환!!!
# ===> 원본 출처는 그대로 두고, box좌표만,,,
# 참고) 여러 방식이 있고, 패키지도 있고,,,etc ==> 여러 방식 중 하나!!
# ----> dl하다보면,,,데이터의 차원/ 데이터의 변형,,./데이터 쌓기..
bboxs = np.stack(
df.loc[:,"bbox"].apply( lambda x: np.fromstring(
x[1:-1],sep=","
))
)
bboxs

bboxs.shape
(147793, 4)
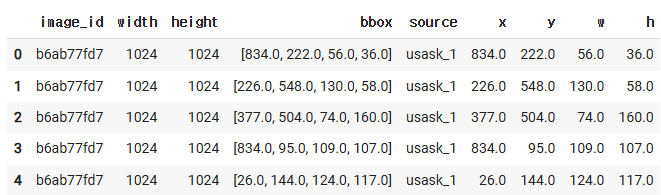
# df에다 yolo중심의 좌표값을 변환을 해서 처리하고 함!!!
# ==> 재료가 kaggle에 준 그 값을 컬럼화!!!!!
for i, col in enumerate(["x","y","w","h"]):
df[col]=bboxs[:,i]
df.head()
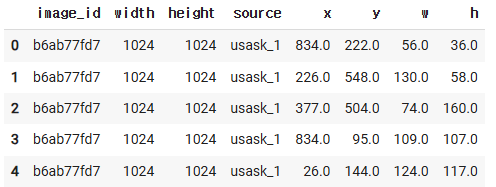
df.drop(columns=["bbox"], inplace=True)
df.head()
# yolo 가 귀찮게도,,,중심 좌표를 사용을 하니...
# ==> W/H는 그대로 사용해도 되고,,, 중심 좌표만 생성!!!
# --> 벡터연산 : numpy --> pandas
df["x_center"] = df["x"] +df["w"]/2
df["y_center"] = df["y"] +df["h"]/2
# =====> yolo 형으로 필요한 좌표 생성!!!
df.head()
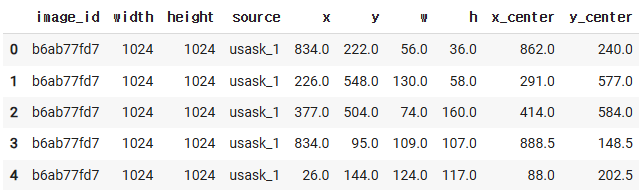
# 우리가 할 모델의 목적 : 품종별 이삭이 아니라!!!!
# ==> 그냥 벼 이삭이면 다 찾아줘!!검출해줘!!
# ==> coco 셋에는 없는 종류!!!(벼 이삭!!)
# ==> 해당하는 종류에 대한 라벨작업!!!
# : yaml 파일로 작성을 해야함!!!!
df["classes"] = 0 # ==> 품종별이 아닐,,박스면 이삭이다!!!!
df.head()
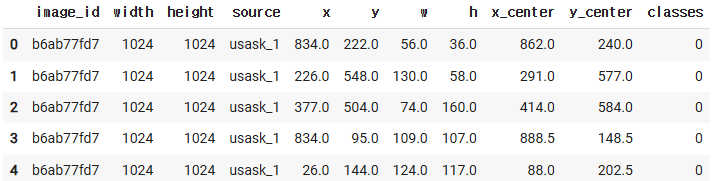
- # ===> train/ val 분리!!!
# ===> yolo도 이미지 : 폴더 구조 세팅!!!!
# - train
# - valid
# - test - # ===> 너무 학습에 오래 걸리다 보니까...수업은 짤라서 진행!!!!!!
# 참고) 뒤에 내용들은 train 전체 데이터로 하는 것은 아님!!!
fold_id = np.zeros( (df.shape[0],1))
fold_id.shape
(147793, 1)
fold_id
array([[0.],
[0.],
[0.],
...,
[0.],
[0.],
[0.]])
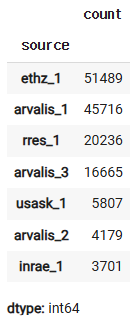
df["source"].value_counts()
skf = StratifiedKFold( n_splits = 5, random_state=1234,
shuffle=True)
# ---> 위에 train 데이터의 지역을 보니,,,불균형성이 있어서,,,
# 중간 검증에 있어서도,,이 부분을 반영해서 하겠다!!!!
# ===> stratifiedK-Flod
# 기존 ml에서는 model.fit(X_triain,y_train, cv=skf )
for (num, (train_index, test_index)) in enumerate(skf.split(df, df["source"])):
fold_id[test_index] = int(num)
df["fold"] = fold_id.copy()
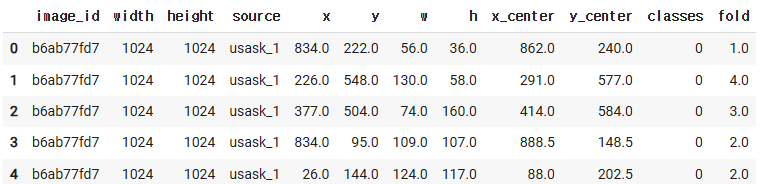
df.head()
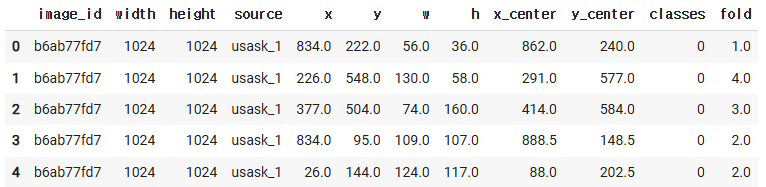
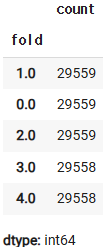
df["fold"].value_counts()
df.head()
# ===> 필요한 정보만 다시 추리겠습니다.
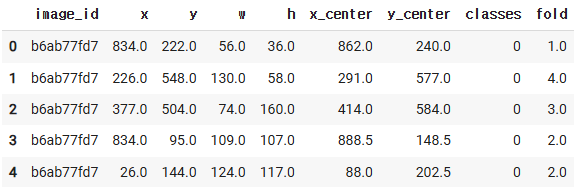
df = df.loc[:, ["image_id", "x","y","w","h",
"x_center","y_center","classes", "fold"]]
df.head()
# YOLO로 학습하기 위해서는 폴더 구조로 세팅!!
source="train"
# ---> **** 시간 관계상 줄여서 하기 위해서,,세트 중에서 0번
fold = 0
val_index= list( df[df["fold"]==fold]["image_id"])
print(val_index)
# 이미지들을 이동을 시킬 예정!!!! ==> 폴더 구조화!!! 코드!!!
import os
# images / train /~~~.jpg
# image / valid / ~~.jpg
# labels / ~~~~
# ////
# image/train/ train.txt(meta) etc
# ===> 저는 편의상..
# converted/fold_0/images/train/~~~~~~
for name, name_data in df.groupby("image_id"):
# name : 이미지 파일의 이름
# name_data : 위의 정보들,,,df에 있는...
if name in val_index:
save_path = "valid/"
else:
save_parh ="train/"
# ===> 참고) 이 문제는 1장에 엄청 많은 이삭 박스가 있음!!!
# 분리의 기준 box 기준을 했기에,,,train.valid
# 거의 동일할 예정임!!!
# 폴더 구조를 생성!!! --> 원하는 폴더가 없으면, 생성하자!!
if not os.path.exists("convert/fold_{}/lables/".format(fold)+save_path):
os.makedirs( "convert/fold_{}/lables/".format(fold)+save_path )
# ==> 원하는 폴더가 있는지 체크하고, 없으면 생성!!!
# 관련된 정보를 yolo 학습을 하기 위해서 메타정보!!!
with open("convert/fold_{}/lables/".format(fold)+save_path+name+".txt", "w+") as f:
# 이미지별로 관련 정보 txt 파일로 생성!!!!
# ==> yolo 기준의 좌표값 : 상대좌표,,,,,,,(전체 이미지 크기)
# 이 셋은 1024로 정해져 있어서,,간략하게 한 것고,아니면 정보를 받아서 계산!!!
# ****
row = name_data[ ["classes","x_center","y_center","w","h"] ].astype(float).values
row = row/ 1024 # 상대 좌표 값으로 변경!!!!!
# ==> classes는 0만 있어서,,,같이 했지만,,나중에는 분리해야함!!!
# 파일에 txt파일에 기록!! ==> 문자 타입으로 해야 파일에 기록
row = row.astype(str)
for j in range( len(row)): # 순서:cls, x_c, y_c, w, h : 옆 공백
text = " ".join(row[j])
f.write(text)
f.write("\n")
# ---> 이미지 별로 txt 파일을 형성!!!!
# 실제 학습을 위한 이미지들을 폴더에 복사!!!or 이동
if not os.path.exists( "convert/fold_{}/images/{}".format(fold,save_path) ):
os.makedirs("convert/fold_{}/images/{}".format(fold,save_path) )
sh.copy("/content/data/{}/{}.jpg".format(source, name),
"convert/fold_{}/images/{}/{}.jpg".format(fold,save_path,name))
#### 원하는 정보들을 다 폴더 구조에 맞춰서 진행을 해야 함!!
# ++++ 메타 정보도 파일로 만들어서 해야 함!!!!
- ### 나중에 프로젝트를 진행을 하는 과정에 있어서도...
### 이런 파일 이동이나, 폴더 생성이나 변경
### 이런 것들을 다 코드로 해두셔야 공유가 수월 함!!!!
# ====> 파일 이동, 폴더 생성, 이동, 복사, 제거 etc 코드화!!!!
# +++ 사용하는 모델에 따라서 데이터셋에 대한 전처리(코드화!!!)
# : 폴더 내에서 이동 + 필요 정보 생성./ 파일 생성,,,, - ### 프로젝트 진행하는 과정에서 참고 되는 github
# 참고) github에는 모델의 weight들을 직접 올리지 않음!!!
# 용량이 커서...
!git clone https://github.com/ultralytics/yolov5.git
- # 참고) 필요한 모델의 weight들 불러오면 됨!!!!
!ls
convert data global-wheat-detection.zip sample_data yolov5
%cd /content/yolov5
/content/yolov5
# 환경 설정에서,,,
# ===> 제시된 패키지 중에서 어떤 부분에서 에러가 나는지 확인!!
# ===> 여기에 빠진 패키지들도 있음!!!
# ===> 버전들을 잡아야 함!!!!( 여러 개가 종속적으로 걸릴 때 ..)
# ===> python버전, os종류와 버전 체크!!!!
# ===> colab 에서 하지 말고, 일반적인 클라우드에서 해야함!!!
!pip install -r requirements.txt
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 53일차 (25.02.25) (0) | 2025.02.25 |
|---|---|
| ASAC 빅데이터 분석가 과정 52일차 (25.02.24) (0) | 2025.02.24 |
| ASAC 빅데이터 분석가 과정 50일차 (25.02.20) (0) | 2025.02.20 |
| ASAC 빅데이터 분석가 과정 49일차 (25.02.19) (0) | 2025.02.19 |
| ASAC 빅데이터 분석가 과정 48일차 (25.02.18) (0) | 2025.02.18 |