8_dl
1_code
7_style
part_01
- 초기 버전 : 이미지의 특성/Feature라는 것이 무엇일까?
==> 기존에 모델들을 어떻게 이용해서/ 변경해서 하는가!

- 기존 연구들은 위의 그림들을 바탕으로 중요한 특징을 뽑아내서/추출해서
분류에 잘 활용해보자!
=> 기존 연구의 주된 방향성! - 초기 버전 : 기존의 Conv 활용을 해서 Texture 연구를 해보자!
=> 이미지가 가진 특성이라는 것이 무엇일까? ==> 이미지의 스타일!
이미지가 가지고 있는 주된 패턴/특징을 잘 찾아보자
이미지가 가진 기본적인 특성/texture를 잘 나타내지 않을까!
<--> 이미지 내에서 유사한 패턴들이 많을 때 잘 동작을 함
( 모든 것들이 다 잘되는 것은 아닙니다1!!!) => 향후 : 화가 작품!

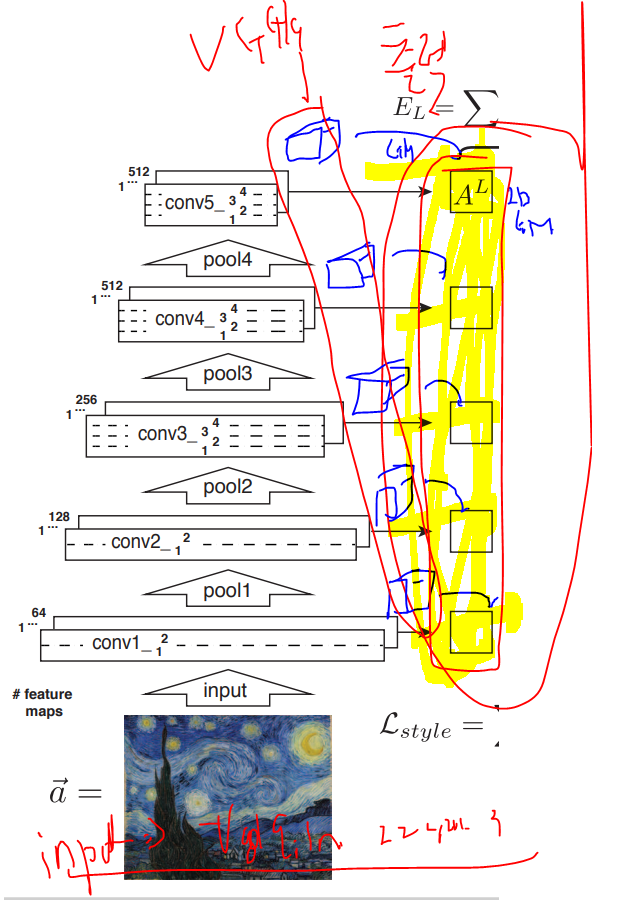
- 왼쪽 그림 : 입력이미지에 Texutre Analysis Part
오른쪽 그림 : Texture Style Part - 왼쪽 : 입력 이미지에 대한 근본적인 특징Feature Map추출!
: 기존 vgg가 이미지에서 특징들을 잘 추출을 하니 그냥 쓰자!! C-C-P
& VGG가 대회에 참가하기 위해서 학습한 weights 그대로 쓰자!
=> 이미지에 특징을 잘 추출하는 외부 모델을 차용!
: Why) 이미 많은 이미지 분류에서 잘 하고 있으니,,이미지의 특징을 잘 뽑았으니!
: 단) 각 단계별로 Conv Block별로 나오는 FM을 output 사용!

- 오른쪽 : 입력( Random Noise : 화이트노이즈)
: 일반적인 네트워크 학습에 있어서도 가중치를 radnom --> GD-->갱신!
( 랜던한 픽셀의 값에서 GD) --> 각 Conv Bolck 의 FM이 유사하도록!
=> 랜덤한 노이지 이미지 ==> 입력 이미지가 되도록!(유사하게!)
=> 나의 목적을 위한 적당한 모델의 구조가 무엇일까!
: 기존 모델의 구조 & 변경 & 변형!
나의 목적에 맞는 네트워크를 어떻게 학습을 할까!
==> 학습의 기준 : Loss Function
: 각 Conv Bolck에서 각기 FM이 어느 정도 유사한지 계량화!
+ 모든 전체 Conv Bolck에서 다 유사해야지 좋겠지!
=> 전반적인 특징을 추출을 하는 것에서 모든 블럭에서 유사하게!
Gram-Matix 방법을 적용!

- 1번 작업 : 차원 변경
=> VGG에서 하게되는 결과에 대한 FM(3D)을 2D Matrix로 어떻게 변경!
=> 각기 채널에 대한 FM을(2D) ---> 1D 벡터로 변경을 하고 모아두자!
3차원을 2차원으로 ( 평면을 1줄로 변경!)


- => 위의 그림에서 보는 것 처럼
Gram Matrix의 목적은 FM에 있는 것들에 대해서 유사성에 대한 계량지표!
+ 채널별로 유사했으면 좋겠습니다!
=> 위와 같은 Gram Matrix로 유사도를 계산을 함!

- *** 인공신경망에 대해서 새로운 관점들 / 바라보는 시각을 던진 것!
==> 성능적인 부분보다는 기존 인공신경망의 활용에 대한 다른 관점
+++ 이럴 때 loss를 어떻게 지정을 하는 것이 좋을까! - *** 중요사항 : Gram Matrix의 개념!
===> 1D 들이 모여있는 2D 상의 Matrix 끼리 유사도에 대한 결과값!
===> 벡터화/ 행렬화 ( 단어 : 1벡터화 --> 문장/글 : 2d matrix)
: Transformer를 이해하실 수 있음! 벡터의 내적!
*** 유사도에 대한 부분을 잘 고민을 해보자!
===> 기본적인 Gram Matrix에 대한 개념을 잘 파악을 해야 함!
part_02
- Image Style Transfer Using Convolutional Neural Networks
==> 본론에 대한 논문입니다!!
1. Image Style Transfer
==> 2개 이미지가 주어졌을 때
1장 이미지 사물의 배치, 정보 : Content 정보
1장 이미지 색/ 질감 : Style 정보
==> 명확하게 어떤 입력이 어떤 것을 담당하는지 구별!
모델명 : A Neural Algorithm of Artistic Style
===> Task중심의 부분에서 활용만이 아니라 "예술"/ 작품 다른 쪽에도 적용할 수 있어!!!

- 크게 네트워크 관점 : 2장 이미지(input) --> 1장 이미지(output)
목적 : 2장 입력 이미지들이 잘 섞인 1장의 이미지를 얻겠다!

- 한계 사항
---> 객관적인 지표가 상당히 애매하다;;; 사람들이 봤을 때 느끼는 갬성과 다름;;
어디까지 갱신이 좋다고 할지 말지...
content/style의 비율은 어찌??
: 껀 바이 껀에 대한 실험!
---> 스타일에 대한 정의가 뭐에요? 명확하게 뭐라고 설명하고, 계량화가 애매함! - # https://keras.io/examples/generative/neural_style_transfer/
# 일단 필요한 패키지 : colab
import tensorflow as tf
import cv2
import tensorflow_hub as hub
import matplotlib.pyplot as plt
- 부분1 : 왼쪽 Stlye 쪽을 먼저 만들어 보겠습니다!
=> 초기 논문인 texture라는 부분을 RN에서 생성!
style_path = tf.keras.utils.get_file("style.jpg", 'http://bit.ly/2mGfZIq')
style_image = plt.imread(style_path)
style_image

## 기존 VGG19를 그냥 가져다가 사용하겠다!
# ==> VGG 학습 : 224,224,3 입력을 받아서,,,출력을 1000으로 Dense
# ==> 입력 이미지의 크기 조정!
# 위의 샘플 : (698, 960, 3) ---> (224,224,3)
style_image = cv2.resize( style_image, dsize=(224,224))
style_image = style_image/ 255.0
plt.imshow(style_image)

# 출력에 용 : 픽셀값을 갱신하려는 최종 출력용
target_image = tf.random.uniform( style_image.shape)
plt.imshow(target_image)

- 일단 목적 : 위의 RN의 이미지의 픽셀값을 잘 갱신해서 입력이미지와 유사하겠다
- 이러한 목적에서 중요한 부분 : 이미지의 특징을 잘 뽑아내자!
==> 이미 잘 이미지의 특징을 뽑아내는 VGG19 모델을 그냥 가져와서 사용하자!
vgg19는 1000종 이미지 분류를 잘 하는 목적!
우리가 필요한 부분 : 앞의 이미지 특징을 추출하는 부분만 가져다가!

- VGG19에서 뒤에 분류는 짤라내고,,,
중간 block에서 FM은 뽑아내고,
--> 내부 weights는 있는거 그대로 사용하고!!
but) 입력 이미지 : 학습한 그대로 224,224,3으로 내가 변경해서 입력하자!
from tensorflow.keras.applications import VGG19
from tensorflow.keras.applications.vgg19 import preprocess_input
# imagenet의 데이트로 vgg19구조 학습한 모델을 그대로 가져오겠습니다!!
# but) 우리의 목적은 1000종류 분류를 사용하는 것이 아니니..
# 출력top은 굳이 필요없어서,,뺄께요!
vgg = VGG19( include_top=False, weights="imagenet")
vgg
for layer in vgg.layers:
print(layer.name)


# ==> 위의 모든 레이어에서 출력을 뽑아낼 수 있지만,,
# Style쪽은 각 블럭 1번에서 추출하겠습니다!!!!
style_layers = ["block1_conv1","block2_conv1",
"block3_conv1","block4_conv1","block5_conv1"]
# 기존 VGG19모델을 있는거 그대로 사용할 것이니까..학습을 전혀 안 할 예정!!!
vgg.trainable = False

# 우리가 원하는 style에 대한 vgg 모델을 설정!!
# ==> in. out의 구조로!!!!
outputs = [ vgg.get_layer(name).output for name in style_layers]
model = tf.keras.Model( [vgg.input], outputs)
# 1장 스타일 이미지 입력 ---> vgg19의 각 블럭 1번 conv 출력들을 모아둔 것 output
# ==> 이런 목적의 하나의 모델로 재설계!!!
# Gram-matirx에 대한 정의!!!! : Loss계산하는 기본 단위!!!!!
def gram_matrix( input_tensor):
# ( 224,224,64) 3D ---> WH를 하나의 1차원 벡터(채널별로 1개의 백터화!!)
# ---> ( 64, 224*224)
# X * X^T =(64, 224*224) * ( 224*224, 64) = (64, 64)
ch = int(input_tensor.shape[-1]) # 채널의 수
x = tf.reshape(input_tensor, [-1, ch] ) # 2D
n = tf.shape(x)[0]
gram = tf.matmul( x, x, transpose_a=True)
return gram/ tf.cast(n, tf.float32)
# 기존의 학습과 다르게 여러 이미지들을 밀어 넣어서 학습을 하는 것이 아님!!!!
# ==> 1장에 대해서 밀어 넣어서 그 결과를 바탕으로 픽셀을 갱신!!!!
# vgg : (None, 224,224,3)
# (600,900,3)---> cv_resize(224,224,3) ----> (1, 224,224,3)
style_batch = style_image.astype("float32") # (224,224,3)
style_batch = tf.expand_dims(style_batch, axis=0 ) # (1,224,224,3)
print(style_batch.shape)
(1, 224, 224, 3)
# 입력 style에 대한 FM을 추출!!!!
# ===> vgg19에서 이미 입력에 대해서 일반적인 부분을 처리하도록 되어 있어서,,
# 중간에 정규화나 이런 여러가지 전처리들을 그대로 사용할 때
# vgg19가 모델에 넣기 전에 처리한 프로세스스 들을 그대로 할지 말지....
style_output = model( preprocess_input(style_batch*225.0))
len(style_output)
5

# 기존 VGG19를 사용해서는 일반적인 각 블럭의 FM(3차원)얻을 수 있음!!
# ==> 우리의 목적에 의해서는 Gram-Matirx로 채널중심의 정보로 가공한 결과
# 타겟으로 하려고 해서임!!! 2D화 시킬려고 (채널중심!!!)
style_outputs = [gram_matrix(out) for out in style_output]
len(style_outputs)
5
style_outputs[0].shape
TensorShape([64, 64])
- # ===> 위의 논문상의 그림으로 표현한 것 까지!!!!
- ---> 다음 시간에 이어서 할 부분
:노이즈를 vgg 태워서 gram-matix
:loss 함수를 직접 지정!!!
: 네트워크의 wiehtg를 갱신하는 것이 아니라ㅏ,,
: 노이지의 픽셀값을 갱신!!!!( 내가 정한 loss를 줄일 수 있도록 학습!!)
===> 이 부분을 어떻게 코드화 할 것인가!!!
++++++++ content 쪽에서 나온 FM의 gram-matrix와 loss을 어떻게 결합할까!!!!
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 56일차 (25.02.28) (0) | 2025.02.28 |
|---|---|
| ASAC 빅데이터 분석가 과정 55일차 (25.02.27) (0) | 2025.02.27 |
| ASAC 빅데이터 분석가 과정 53일차 (25.02.25) (0) | 2025.02.25 |
| ASAC 빅데이터 분석가 과정 52일차 (25.02.24) (0) | 2025.02.24 |
| ASAC 빅데이터 분석가 과정 51일차 (25.02.21) (0) | 2025.02.21 |