8_dl
1_code
8_lstm
- Seq 데이터에 대한 모델링!
RNN --> LSTM으로 간단하게 보겠습니다.
: 주가 데이터를!
# 주가 데이터 : pandas --> yfinance
!pip install yfinance
- 주가 데이터 : 시/종/고/저 + 거래량 --> 날짜별
일별 데이터// 분 // 초 // 틱 // etc
===> HTS 많은 지표들은 기본적으로 5가지 특징/Feature를 사용해서!!
import yfinance as yf
# ticker 중심으로 요청하는 종목명, 기간
data = yf.download( "NVDA", start="2020-01-01")
data.head()
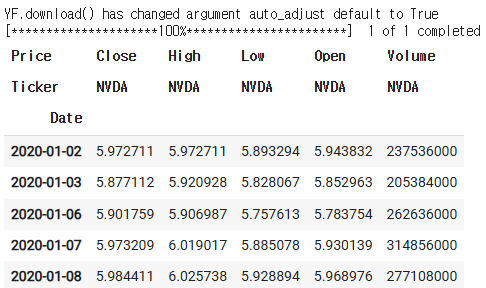
import pandas as pd
data.columns

data["Close"].plot()

- 가정 : 종가를 기준으로 seq 이용해서 예측을 하자!
closing_prices=data["Close"].values.reshape(-1, 1) # ---> 수정 종가 등이 있거나 모양이 안 맞을 때
closing_prices # 모양 : ( n, 1)

# 입력 데이터 정규화 : 편의상....
from sklearn import preprocessing
from sklearn.preprocessing import MinMaxScaler
# ===> 처리하다 보면 필요한거, 편한 패키지들 잘 가져다가 사용하시면 됨!!
# 종가에 대해서 고가를 기준으로 0~1사이의 값으로 재조정!!!!
scaler = MinMaxScaler( feature_range=(0,1))
closing_prices_scaled = scaler.fit_transform(closing_prices)
closing_prices_scaled

pd.DataFrame(closing_prices_scaled).plot()

# 데이터를 재가공을 위해서 처리
import numpy as np
# 3일/ 5일 / 20일 ---> n_step
# ==> 꼭 이렇게 해야합니다가 아니라,,,,데이터의 모양을 신경써야 한다!!
# 입력 : 여러개의 seq ----> 모양을 세팅!
# X(time_1,time_2, time_3,,,,,,,)
def prepare_data( data, n_step):
x = []
y = []
for i in range(len(data)-n_step):
x.append( data[i:(i+n_step), 0]) # 전 5일 종가 : D-1~~~D-5(입력)
y.append(data[i+n_step,0]) # D-Day 주가 (출력)
# 입력seq( 전 5일 종가) ----> 출력seq( 오늘 종가 )
return np.array(x), np.array(y) # --> 문제, 정답지

# --> 하려고 하는 일 : 저는 1달을 기준으로 전일 20일의 종가 데이터의 흐름을 바탕으로
# 그 다음날의 종가를 예측!!!
n_step = 20
# *** 수집한 데이터는 날짜별로 수집!!!!
# 모델을 위해선,,,,in./ out의 구조를 모델에 맞춰서!!!!!
# 5일 종가 in (X) // 다음 날 종가 out(y)
X, y = prepare_data( closing_prices_scaled, n_step)
X.shape
(1279, 20)
y.shape
(1279,)
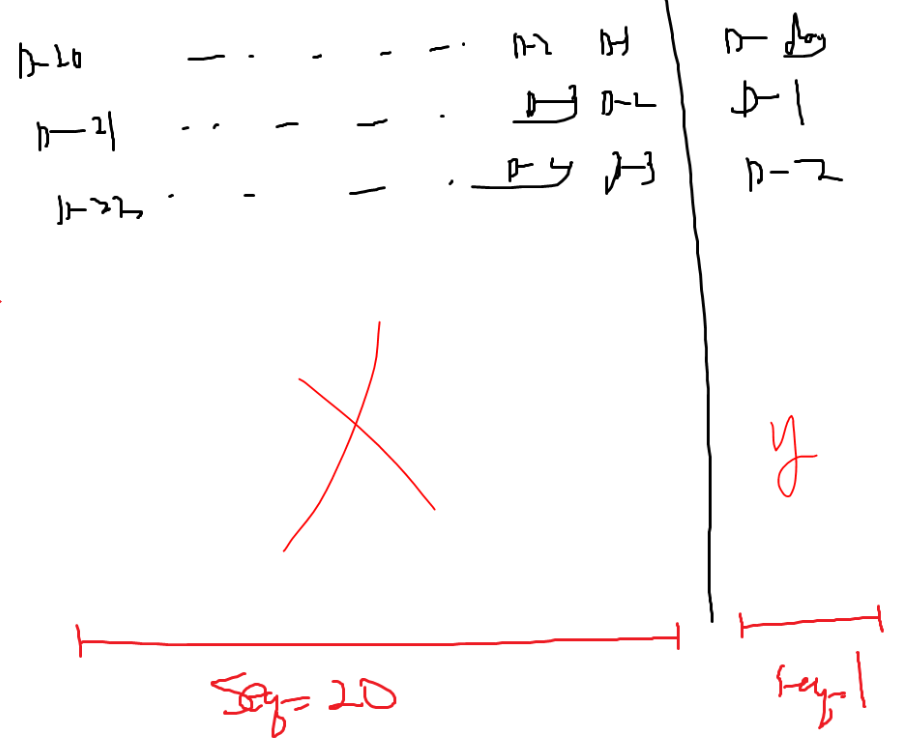
# *** DL을 돌리기 위해서는,,,Batch_size를 대한 고민을 하면서 짜야함!!!
# ===> DataSet 관점으로 봐야 함!!!!
# ( 1279, 20) -->> ( 1279, 20, 1)
X = np.reshape( X, (X.shape[0], X.shape[1], 1))
X.shape
# ===> 세팅한 모델에 따라서 유연하게 생각하셔야 하고, 변경!!!
# LSTM에 입장에서는 1개 샘플이 (20,1) 들어가도록 해야해서...
(1279, 20, 1)
# 학습과 평가에 대해서 나눌 때 : 일반적은 RandomSample
# : seq/시계열 특정시점중심!
# ==> 사용하는 도메인에 따라서 평가 방식은 조금 다를 수 있음!!
# (롤링하면서 평가하건 하는 경우도 있음1 case by case)
x_train = X[:1000, :] # 수집 시점 부근부터,,1000일 동안, 20일이 과거 내역 X
y_train = y[:1000] # 수집 시점 부근부터,, 1000일 동안 가격,,
x_test = X[1000:, :]
y_test = y[1000:]

import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, LSTM
def create_lstm_model( input_shape):
model = Sequential()
model.add( LSTM( input_shape=input_shape,units=50,return_sequences=True ))
model.add( LSTM(units=50)) # return_seqence를 설정하지 False: 맨 마지막만
model.add(Dense(units=1)) # AF : skip
#
model.compile( optimizer="Adam", loss="mean_squared_error")
# ==> mse, rmse etc....
return model
x_train.shape[1]
20
model_1 = create_lstm_model( ( x_train.shape[1], 1))
model_1
model_1.summary()

from tensorflow.keras.utils import plot_model
plot_model(model_1, show_shapes=True)

- ==> 아래 그림처럼...
단순 설명용 그림에서 점 하나가 진짜 값 하나가 아님!
RNN - LSTM etc 점 하나에....레이어 1개==> 여러 노드가 있을 수 있음!
1개 점 : Scalar가 아니라,,1D Vector로 생각!


- ==> 입력 데이터 : ( 샘플의 수, 입력seq길이, 1시점의 정보의 수)
( 1900일동안데이터, D-1~D-20 20길이, 종가1개)
===> if) t 시점의 정보 : t날의 종가 ,t날의 고가, 시가, 거개량,,,
(1900, 20, 4(t시점 종가/고가/시가/거래량......))
model_1.fit(x_train, y_train, epochs=10, batch_size=32)

# 학습한 결과 test에 적용!!!!! --> 실제와 얼마나 잘 맞는가??
# ==> train에서도,,,
train_ypred = model_1.predict(x_train)
train_ypred = scaler.inverse_transform( train_ypred)
train_ypred
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
plt.plot( data.index[n_step:1000+n_step], closing_prices[n_step:1000+n_step],
label="RealStockPrice", color="blue")
plt.plot( data.index[n_step:1000+n_step], train_ypred,
label="TrainedStockPrice", color="red")
plt.xlabel("Date")
plt.ylabel("Stock Price USD")
plt.legend()
plt.show()

# 실제 test 데이터를 처리!!!!
# ==> 학습에 전혀 사용하지 않은 데이터!!!!!평가!!!
test_pred= model_1.predict(x_test)
test_pred = scaler.inverse_transform(test_pred)
test_pred
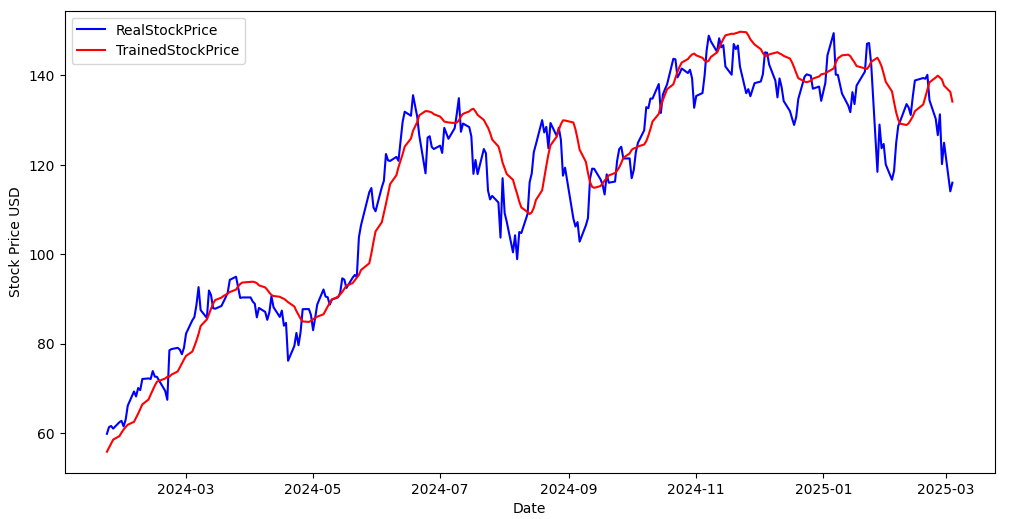
plt.figure(figsize=(12,6))
plt.plot( data.index[1000+n_step:], closing_prices[1000+n_step:],
label="RealStockPrice", color="blue")
plt.plot( data.index[1000+n_step:], test_pred,
label="TrainedStockPrice", color="red")
plt.xlabel("Date")
plt.ylabel("Stock Price USD")
plt.legend()
plt.show()
- 정리!!!
===> RNN계열의 모델에서 주의할 점!!! - 1. 수집하는 데이터의 모양과 다를 수 있음!!!!!
- 2. Seq에 대한 정의를 정확하게 해야 함!!!
입력에 대한 고려 사항 : t시점 기준으로 어떤 정보!!!(t시점에서)
----> seq의 길이는 얼마?
ex) t날 : 종가,(+시가,저가,고가,거래량) x점하나로 표현 vector
과거 5일 --> 예측, 과거 20일로 --> 예측
출력에 대한 고려 사항 : seq 뽑을지, 최종 시점에서 1개로 뽑을 etc
===> 내가 설정한 대로 데이터를 재형성을 해야함!!!!!!! - 3. 모델의 구조 : 간략화된 그림 vs 실제 내용과 연결!!!!!
===> 점 하나가 스칼라인지 vs 벡터 주의해서 보시면 좋습니다!!!!
===> in/out관점으로 잘 보셔야 함!!!
+++ 그림상 : 옆으로는 seq 길이/ time에 대해서 그림!!(가로)
쌓는다 : 위로(세로)
: 기존과 다르게 돌려서 고렿하시면 됨!!!!
==> 펼치는 방향(seq길이) + 쌓는 방향( 구조 )
# 결론 : 원하는 구조 + 그 구조에 맞는 데이터 형성!!!!
*시계열이 대충은 따라가는 것 같다.
=> 정밀하게는?
=> 실제 사용은?
--주가 데이터 예측 : 심플
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 60일차 (25.03.07) (1) | 2025.03.07 |
|---|---|
| ASAC 빅데이터 분석가 과정 59일차 (25.03.06) (0) | 2025.03.06 |
| ASAC 빅데이터 분석가 과정 57일차 (25.03.04) (0) | 2025.03.04 |
| ASAC 빅데이터 분석가 과정 56일차 (25.02.28) (0) | 2025.02.28 |
| ASAC 빅데이터 분석가 과정 55일차 (25.02.27) (0) | 2025.02.27 |