농심의 Amazon SageMaker를 활용한 원자재 가격예측과 MLOps 여정
농심의 Amazon SageMaker를 활용한 원자재 가격예측과 MLOps 여정 | Amazon Web Services
농심은 1965년 창립 이후 50여 년 동안 한국의 식문화를 이끌어온 식품 전문 제조기업입니다. 농심은 글로벌 식문화 창조기업으로의 도약을 위해 비전 2025를 수립하고 이에 맞는 중장기 목표와 사
aws.amazon.com
서비스 개발 목표
이번 서비스 개발의 목표는 실무 담당자가 데이터를 내려받는 과정에 들어가는 불필요한 인력, 시간 자원을 최소화하고 데이터 기반의 의사결정 및 체계적 구매전략 수립을 위해 AWS SageMaker를 활용한 MLOps 아키텍처를 구성했습니다. 이를 통해 농심 내부 효율적인 프로세스를 확립하고 머신러닝(AI/ML)을 활용한 시계열 예측 기술을 적용하여 일관성 있는 구매전략을 기대합니다.
업무의 효율성 및 빠른 의사 결정 속도를 위해 기존 비즈니스 담당자가 수작업으로 이루어지던 데이터 수집부터 AI/ML 모델을 학습하고 배포하는 단계까지 자동화하는 MLOps 아키텍처 구축의 필요성, SageMaker를 통해서 향후 농심의 타 AI 서비스에도 적용할 수 있는 AI 서비스 아키텍처 템플릿을 구축하는 필요성 역시 대두되었습니다. 따라서 데이터, AI 모델, 아키텍처 3가지 측면에서 요구사항을 세분화하였습니다.
1. 데이터: 구매담당자가 원자재 가격을 예측하는 데에 사용해온 데이터 수집
- 내부 데이터: 농심 SAP ERP 팜유 구매 실적 데이터
- 외부 데이터: 원산지의 기후 데이터 (ex 일조량, 강수량 등), 연관 원자재(ex 소맥, 대두유 등), 세계 경기 지수(ex 상해 지수, 나스닥 지수 등)
2. AI 모델: AutoGluon
- AWS lab에서 개발한 AutoML 라이브러리인 AutoGluon을 포함한 다양한 모델 사용
3. 아키텍처: Amazon SageMaker
- 데이터 수집부터 AI 모델 배포까지 AI 라이프사이클을 자동화하고 AI 모델을 관리하기 위한 MLOps 아키텍처 구축
- AI 모델 배포 전, 비즈니스 담당자가 다양한 모델을 테스트한 결과를 확인한 후 선택할 수 있는 파이프라인
원자재 가격 예측 자동화 시스템의 세부 사항
농심에서는 On-premise를 AWS로 마이그레이션하는 차세대 프로젝트를 1년 이상 진행하고 있습니다. 이에 따라 AWS 환경이 사내 개발자 및 데이터 사이언티스트에게 친숙합니다. 그러나, 그들이 진행하는 AI/ML 프로젝트의 경우 다양한 인프라에 각기 다른 아키텍처로 구축되어 있습니다.
Amazon Sagemaker는 AWS 리소스와 연계가 쉽고 데이터 분석부터 기계 학습(ML) 모델을 빠르게 훈련, 배포하고 모니터링까지 가능한 완전 관리형 서비스입니다.
단일화된 플랫폼을 구축함으로써 얻을 수 있는 효과는, 데이터 사이언티스트에게는 친숙한 Jupyter notebook 환경인 Studio notebook과 데이터 변환 서비스인 Data Wrangler를 제공하여 데이터 정제, 분석을 손쉽게 할 수 있습니다. 또한, AI/ML 엔지니어에게는 Sagemaker Training을 활용하여 여러 AI 모델을 훈련시키고, Sagemaker experiments, Model Registry로 고도화를 위해 수행되는 여러 개의 머신러닝 모델들을 실험 및 성능 모니터링하여 최적의 모델을 선택할 수 있습니다. AI 모델 제작 이후에도 모델 서빙 및 모니터링에 필요한 사후 관리 서비스를 제공한다는 점과 AWS 리소스를 활용한 아키텍처 관리가 용이하다는 강력한 장점에 Amazon Sagemaker 가 사용되었습니다.

아키텍처 구성 항목들:
- 데이터 수집: 농심 SAP에서 원자재 구매 실적 데이터와 예측 변수로 사용될 외부 데이터를 수집하여 DataLake 역할을 하는 S3에 적재되는 로직이 구현되는 곳입니다.
- 데이터 추출: 적재된 DataLake에서 Use-Case에 맞는 Stage data를 추출하여 적재하는 로직이 구현되는 곳입니다.
- 데이터 정제: 추출된 Stage data를 불러와서 머신러닝(AI/ML) 입력값에 맞게 정제된 golden data로 변환하여 적재하는 로직이 구현되는 곳입니다.
- 모델링: 정제된 golden data를 불러와서 머신러닝(AI/ML) 학습 이후 모델 파일과 모델 결과를 적재하는 로직이 구현되는 곳입니다.
- 모델 검증: 모델 배포가 진행되기 전에 1차적으로 모델 검증을 거치는 단계입니다. 가령, 사용자가 설정한 모델 성능 최소 요구조건을 넘겼을 때에만 AI 모델 저장소인 Model Registry에 저장됩니다.
- 모델 배포: 최종 검증을 진행하여 AI 모델이 배포되는 로직이 구현되는 곳입니다. 검증을 통과한 모델의 예측 결과는 시각화 되어 구매 담당자가 직접 확인하고 비즈니스 목표가 달성됐을 때 Approve 버튼을 누르면 서비스가 배포됩니다.
Amazon SageMaker와 Airflow를 이용한 SK브로드밴드의 MLOps 플랫폼 구축 사례
Amazon SageMaker와 Airflow를 이용한 SK브로드밴드의 MLOps 플랫폼 구축 사례 | Amazon Web Services
SK브로드밴드는 ASDL 상용화, Pre-IPTV 서비스 제공 등 통신 방송 시장을 선도하며, 동시에 미디어 비즈니스 모델 다변화를 통한 종합 미디어 플랫폼 기업으로 성장하고 있습니다. SK텔레콤과 One Body
aws.amazon.com
프로젝트 배경 및 목표
데이터 수집부터 모델 배포까지의 전 과정을 자동화하고, 모델과 예측 내용을 현업에 적시에 제공할 수 있는 플랫폼 구축이 핵심 목표였습니다. 또한, 엄격한 모델 버전 관리와 재현성 확보, 실시간 및 배치 추론 파이프라인 구축, 그리고 자동화된 모델 성능 모니터링 시스템 구현도 주요 목표였습니다.
Amazon SageMaker를 활용한 파이프라인 구축과 거버넌스 구현
SK브로드밴드는 MLOps 시스템의 빠른 구축과 효율적인 운영을 위해 Amazon SageMaker를 핵심 플랫폼으로 선택했습니다. 또한 워크플로우 관리를 위해 Apache Airflow를 자체적으로 구축하여 운영하기로 결정했습니다. 이러한 선택은 SK브로드밴드의 특수한 요구사항을 충족시키면서도 클라우드의 장점을 최대한 활용할 수 있는 방안이었습니다.
Amazon SageMaker 선정 이유
- AI/ML 모델 개발 전반에 걸친 종합적인 다양한 기능을 제공
- 컨테이너 기반 서비스로 알고리즘의 일관성 보장 및 유연한 커스터마이징 가능
- 사용한 리소스에 대해서만 학습 비용을 지불하는 비용 효율적인 모델
- Amazon SageMaker SDK를 통한 다양한 커스터마이징 옵션
Apache Airflow 자체 구축 이유
- 유연성과 커스터마이징
- 자체 구축을 통해 SK브로드밴드의 특수한 요구사항에 맞춰 Airflow를 최적화할 수 있었습니다.
- ML 워크로드 지원을 위해 필요한 Executor들의 사용이 가능했습니다.
- 자유로운 버전 관리
- AWS MWAA는 Airflow 버전 업데이트가 제한적인 반면, 자체 구축을 통해 최신 버전의 Airflow를 신속하게 도입할 수 있었습니다.
주요 기술 스택
- 모델 개발 및 배포
- 워크플로우 관리
- 데이터 파이프라인
SK브로드밴드의 모델 거버넌스를 중심으로 한 MLOps 아키텍처

SK브로드밴드는 SageMaker를 중심으로 ML 라이프사이클의 각 단계를 통합하면서도, Apache Airflow를 통해 유연한 워크플로우 관리를 가능하게 한 MLOps 아키텍처를 설계했습니다. 핵심 구성요소는 다음과 같습니다.
- 데이터 레이크: Amazon Simple Storage Service(Amazon S3)를 사용해 원본 데이터와 중간 처리 결과를 저장
- 모델 개발 환경: SageMaker Notebooks 탐색적 데이터 분석 및 모델 프로토타이핑
- 모델 훈련 및 평가: SageMaker Training Jobs와 Processing Jobs 활용
- 모델 레지스트리: SageMaker Model Registry로 모델 버전 관리
- 모델 배포: SageMaker Endpoints(실시간 추론)와 Batch Transform(배치 추론) 사용
- 워크플로우 관리: 자체 관리형 Apache Airflow로 전체 파이프라인 오케스트레이션
- 모니터링: Amazon CloudWatch로 모델 및 인프라 모니터링
여러 개의 컴퓨터 시스템, 애플리케이션 및/또는 서비스를 조율하고 관리하는 것
파이프라인 오케스트레이션 : 여러 개의 파이프라인을 조정하고 관리하는 개념
티머니의 MLOps 구현 사례 : Amazon SageMaker를 활용한 배차모델 자동화 및 배포
티머니의 MLOps 구현 사례 : Amazon SageMaker를 활용한 배차모델 자동화 및 배포 | Amazon Web Services
이 블로그는 티머니의 반용주 매니저, 구현서 매니저, 오지훈 매니저와 함께 작성되었습니다 티머니는 ‘이동을 편하게, 세상을 이롭게’를 경영철학으로, ‘더 편한 이동과 결제를 위한 플랫
aws.amazon.com
티머니GO온다택시의 호출 성공율을 높이기 위해 ML모델을 개발하고, 예측 정확도 유지를 위해 티머니에서 진행한 다양한 노력과 프로세스 혁신의 과정을 소개합니다. 특히, 온프레미스에서 자체 개발한 머신러닝(ML) 모델을 Bring Your Own Model(BYOM) 방식으로 배포하여 Amazon SageMaker 기반에서 서비스한 부분과, MLOps를 활용하여 머신러닝 라이프사이클을 자동화한 여정을 다룹니다
ML모델 재학습 및 재배포를 위한 Amazon SageMaker 선택
티머니는 이미 로컬 환경에서 개발하고 학습한 예측 모델을 보유하고 있었습니다. 따라서 이번 프로젝트의 목표는 이 모델의 성능을 유지하면서 클라우드 환경으로 마이그레이션하고, 자동화된 CI/CD 파이프라인을 구축하는 것이었습니다. 아울러 아래와 같은 사항을 고려했습니다.
- Amazon SageMaker의 완전 관리형 서비스 특성은 MLOps 전문 인력이 부족한 상황에서도 큰 장점을 제공했습니다. 모델 구축부터 학습, 배포에 이르는 전 과정을 효율적으로 관리할 수 있어 SageMaker 도입을 결정하게 되었습니다.
- 티머니는 SageMaker Script Mode는 BYOM(Bring Your Own Model) 접근 방식을 채택했습니다. Script Mode를 활용하면 AWS에서 제공하는 베이스 모델 컨테이너(XGBoost, PyTorch, TensorFlow 등)를 기반으로, 기존 모델을 활용하면서도 티머니의 자체 학습 및 추론 코드를 그대로 사용할 수 있었습니다. 이 방식은 기존에 개발한 ML모델을 클라우드 환경으로 신속하게 마이그레이션할 수 있어 모델 배포 관리에 대한 부담을 최소화하면서도 지속적인 모델 개선과 효율적인 운영을 가능하게 했습니다.
- SageMaker Notebook Jobs를 활용하여, 모델 투입 변수 업데이트 및 학습 작업을 자동화할 수 있었습니다. 온다택시의 마이그레이션 된 ML모델은 매월 지속적으로 업데이트가 필요합니다. 특히 수요와 공급을 대표하는 데이터의 분포 변화는 택시 호출의 성공확률에 큰 영향을 미치기 때문에, 이를 놓치지 않고 모델에 반영하는 것이 중요했습니다.
- SageMaker Pipelines을 구축하여 주기적인 모델 학습, 배포, 업데이트 및 버전 관리를 가능하게 했습니다.
- SageMaker Endpoint를 생성해서 배포된 모델에 대해 실시간으로 추론할 수 있었습니다. 프로젝트의 목적이 택시 호출에 대해 실시간으로 평가를 하고 조치를 취하는 것이기 때문에 SageMaker Endpoint가 중요한 역할을 했습니다.
솔루션 아키텍쳐와 흐름도
티머니는 로컬에서 모델 개발 당시 가장 좋은 성능을 보인 XGBoost 모델을 사용했습니다. XGBoost는 지도학습 기반 그래디언트 부스팅 알고리즘을 사용하는 대중적인 오픈소스 ML모델입니다.
XGBoost 알고리즘을 사용하기 위해서는 Amazon SageMaker AI의 내장 알고리즘 또는 로컬 환경에서 학습 스크립트를 실행하기 위한 프레임워크로 사용할 수 있습니다.
BYOM을 진행할 때 Amazon SageMaker XGBoost Bring Your Own Model 방식을 활용하여 학습된 모델을 S3로 업로드하고 SageMaker Endpoint에서 호스팅하는 방법도 가능합니다. 티머니는 커스텀 학습 및 추론 코드를 AWS 클라우드에 올려서 모델을 매월 새로 학습, 배포하는 형태로 진행했습니다.
이후 MLOps 파이프라인을 구성하여 주기적인 데이터 전처리, 모델 학습, 평가, 모델 등록, 그리고 엔드포인트 배포까지의 모든 과정을 자동화했습니다. 이 흐름은 Amazon SageMaker Pipelines, Amazon SageMaker Processing Job, SageMaker Training Job, 그리고 SageMaker Endpoint를 이용해 단계별로 이루어졌으며, 모든 단계가 유기적으로 연결되어 전체적인 ML 라이프사이클을 효율적으로 관리할 수 있도록 설계되었습니다.

아래는 SageMaker Studio의 Visual Designer 기능을 활용하여 ML 워크플로우를 시각화한 화면 입니다.
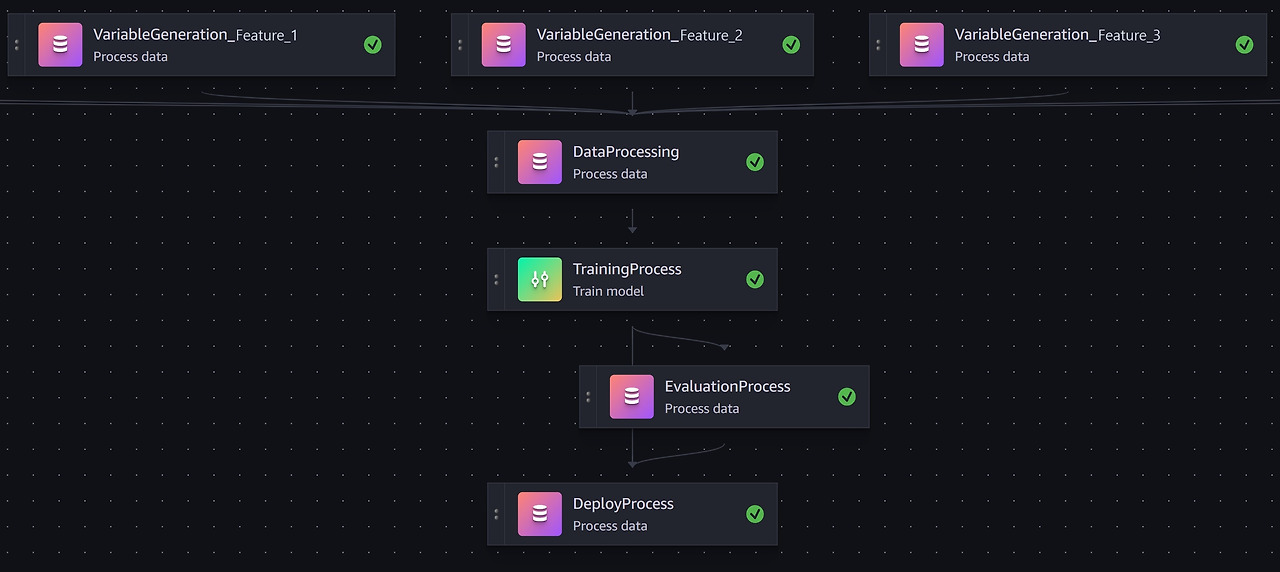
SageMaker BYOM 및 Pipeline 구현 상세
1. 로컬 모델 개발 및 평가
최초 모델 개발은 로컬 환경에서 시작했습니다. 이 과정에서 주력한 부분은 다음과 같습니다:
- 변수 생성 및 테스트: 호출 성공확률에 영향을 미치는 수요와 공급 관련 변수들을 생성하고 테스트했습니다.
- 모델 개발 및 평가: 유의미한 변수들을 선별하여 모델에 투입하고, 개발 및 평가 과정을 거쳤습니다.
- 성능 최적화: 특히 두 가지 핵심 지표에 주목했습니다.
- Recall Score: 실제 성공한 호출을 정확히 예측하는 능력을 평가합니다.
- Precision Score: 불필요한 비용 지출을 줄이기 위한 정확도를 평가합니다.
티머니는 이 두 지표를 만족스러운 수준으로 높이기 위해 여러 차례의 반복 작업을 수행했습니다. 최종적으로, 개발한 모델은 Hyper-Parameter Optimization (HPO) 과정 없이도 충분히 만족스러운 성능을 보여주었습니다. 이로써 로컬환경의 모델 개발 과정은 마무리 지었습니다.
로컬환경에서 모델 개발을 위해 작성했던 데이터 전처리, 학습/평가 데이터 생성, 모델 개발 파이썬 코드는 SageMaker Pipeline 생성을 위해 S3 버킷의 작업경로에 저장했습니다.
2. SageMaker Pipeline 생성
SageMaker Pipeline은 머신러닝 워크플로우를 자동화하고 관리하는 강력한 도구입니다. SageMaker Pipeline은 UI, SageMaker Python SDK 또는 SageMaker Pipeline Definition JSON 스키마를 사용하여 빌드할 수 있습니다.
초기에 티머니는 AWS 환경에서 ML모델 학습 및 배포를 SageMaker Pipeline 없이 진행했습니다. 그러나 머신러닝 모델을 매월 주기적으로 재학습하고 배포해야하는 요건이 있었기 때문에 MLOps를 초기 ML모델 배포 성공 이후 검토하여 적용했습니다.
3. 변수(Feature) 생성 단계
SageMaker Processing Job은 SageMaker 의 완전 관리형 인프라에서 데이터 사전 및 사후 처리, 기능 엔지니어링 및 모델 평가 작업을 실행할 수 있습니다.
티머니는 Processing Job을 활용하여 AWS 클라우드에 저장된 Raw data를 활용하여 모델에 투입할 변수를 생성하였습니다.
또한, 데이터 전처리를 위한 변수 생성 단계에서는 빅데이터팀 이외에도 엔드포인트를 실제로 사용하는 애플리케이션팀과의 협업이 중요했으며, 데이터의 버전 관리를 통해 추적 가능성을 높였습니다. 생성된 변수들은 Amazon Simple Storage Service (Amazon S3)에 저장되어 이후 학습 및 평가 데이터 생성 단계에서 사용되었습니다.
4. 데이터 전처리 단계 : 학습 및 테스트 데이터 세트 생성
다음은 이전 변수 생성 단계를 통해 S3에 저장된 각 변수 데이터를 기반으로, 학습 및 테스트 데이터세트를 생성하는 단계입니다.
5. 모델 학습, 평가 및 저장 단계
아래는 SageMaker Pipeline을 활용한 모델 학습, 평가 및 저장 과정을 설명합니다. (일부 정보는 고객사 주요 정보로서 생략하였습니다.)
모델 학습 스크립트
다음은 학습 단계로서 이전에 생성된 학습/평가 데이터 세트를 활용합니다. ML모델 학습은 XGBoost Estimator를 사용하여 사용자 지정 학습 스크립트를 구성했습니다. 하이퍼파라미터는 이전 로컬 개발의 평가 결과를 바탕으로 고정된 값을 사용하여 XGBoost 모델에 딕셔너리 형태로 정의합니다.
SageMaker Training Job을 사용하면 학습 스크립트에서 사용
SageMaker Training Job을 사용하면 학습 스크립트에서 사용자 지정 지표를 게시하여 시간 경과에 따른 교육 진행 상황을 추적할 수 있습니다.이러한 지표는 SageMaker Experiment, SageMaker Console 및 Amazon CloudWatch를 통해 직접 볼 수 있습니다.
모델 평가 스크립트
아래 샘플 코드는 Processing Step을 사용하여 모델을 평가하는 방법을 보여줍니다.
Processing Step에서는 학습 단계의 프레임워크 버전과 동일한 XGBoost 프로세서를 사용합니다. 이에 따라 제공된 평가 스크립트를 실행하는 데 사용되는 컨테이너가 결정됩니다.
모델 저장
이렇게 학습된 모델은 Amazon SageMaker Model Registry에 저장하여 버전 관리를 수행했습니다. 이렇게 저장된 모델은 새로운 데이터로 업데이트할 수 있도록 관리되었습니다. 만약 기존에 SageMaker Endpoint에 배포된 모델과의 성능 비교 Evaluation을 통해 성능 요구사항에 미치지 못할 경우 재학습하도록 하였습니다.
6. 모델 배포 및 추론 단계
아래는 ML모델 배포 및 추론 과정 샘플 코드입니다. 이를 통해 ML모델 배포 과정을 자동화하고, 파이프라인의 일부로 통합하여 모델을 실제 서비스에 적용하는 과정을 간소화합니다.
7. MLOps 구성 및 자동화
MLOps는 Amazon SageMaker Pipelines를 사용해 구성되었습니다. 이 파이프라인은 데이터 전처리, 모델 훈련, 평가, 등록, 배포의 모든 단계를 자동으로 실행하며, 각 단계 간의 종속성을 설정하여 전체 ML 워크플로우가 원활하게 이루어지도록 했습니다.
티머니는 매월 학습, 참조 데이터가 주기적으로 변경되는 상황에서 학습 데이터 전처리를 위한 ‘실행파일.py’도 주기적으로 변경되기 때문에 이를 엔드 투 엔드로 자동화하는 방향을 검토했습니다.
다양한 방법을 검토한 끝에 2023년에 출시한 SageMaker Notebook Job을 적용하여 문제를 해결하였습니다. JupyterLab 내 Notebook Job extension을 활용하면 Scheduling Job을 별도의 Amazon Event Bridge 또는 AWS Lambda 함수를 구성하지 않고도 손쉽게 구성할 수 있습니다.

온프레미스의 모델을 SageMaker Endpoint로 배포하는 방법은 BYOM 예제 코드를 참고 하시면 되며,AWS 공식 GitHub의 MLOps 예제에서 더 많은 예시 코드를 확인할 수 있습니다.
amazon-sagemaker-examples/ ml_ops at default · aws/amazon-sagemaker-examples
Example 📓 Jupyter notebooks that demonstrate how to build, train, and deploy machine learning models using 🧠 Amazon SageMaker. - aws/amazon-sagemaker-examples
github.com
SageMaker를 더 잘 활용하기 위해 aws-samples 내 AWS AIML 한글워크샵 모음 공식 GitHub을 방문 해보시길 바랍니다.
aws-ai-ml-workshop-kr/sagemaker at master · aws-samples/aws-ai-ml-workshop-kr
A collection of localized (Korean) AWS AI/ML workshop materials for hands-on labs. - aws-samples/aws-ai-ml-workshop-kr
github.com
'Project > 기업 연계 프로젝트' 카테고리의 다른 글
| ASAC 4기 최종 발표 정리 (0) | 2025.03.31 |
|---|---|
| [이론] 선형 계획법 (0) | 2025.03.28 |
| [이론] 재고 관리 최적화 (0) | 2025.03.28 |
| [하닉식스] Data 해석 - pump_oper_history (0) | 2025.03.24 |
| [하닉식스] Data 해석 - pump_cost_master (0) | 2025.03.24 |