Scikit-learn
#파일 다운
!gdown 1Kcc5aR3ZYK8onDhQ6L-JqEyOj3BEuQoL
- 참고) 지금 버전 이슈들이 좀 있는 시기라서
scikit-learn 1.6.X -> xgboost 호환이 안 된다.
-> scikit-learn의 버전을 다운그레이드
#버전 다운그레이드
!pip install "scikit-learn < 1.6"
- 패키지마다, 세션을 다시 꼭 해야지만 변경이 되는 것도 있고
그냥 해도 되는 것들도 있다.
import sklearn
sklearn.__version__
# 이 패키지 같은 경우에는 다시 시작을 하지 않아도 괜찮다.
'1.5.2'
# 기본 패키지
import pandas as pd
import numpy as np
- 전처리를 할 때 : 인코딩 => 라벨인코딩(정수값들) vs 원핫인코딩(0/1)
-> DL을 할 때 정답지의 구성을 원핫인코딩 계열을 자주 사용한다.
from sklearn.preprocessing import LabelEncoder
# 수집한 데이터 or 처리해야할 데이터 or 서버에서 sql로 불러온 데이터
path = '/content/train.csv'
data = pd.read_csv(path)
data.head()
#출력 생략
- 가장 중요한 것은 전처리 전에 EDA를 꼭 해야 한다
ML을 돌리기 전에 전제 조건 : 결측치 없어야 한 & 숫자로 다 되어 있다
- Step1 함수 : 누락된 데이터를 처리
컬럼 : age, cabin, embarked, fare
입력 : df
출력 : 위의 4개 컬럼에 대한 결측치 처리해서, df로 출력
=> 필요에 따라서 수정해서 사용하시면 된다
def check_fillna(df):
# 목적 : 누락된 값 채우자
# => 분석자가 스스로 결정, 왜 그런 결정을 했는지 이유
df.loc[:,"Age"].fillna(df.loc[:,"Age"].mean(), inplace=True )
# => train데이터의 Age의 평균이 기준
# 엄밀하게 하기위해서는 train의 Age 평균을 test에서 Age누락된 값에 채워
# test의 Age의 평균으로 test의 Age 결측값을 채우면?
# cabin/embarked/fare 채워보자
# => 정보 없음의 값 : N,N,0
df.loc[:,"Cabin"].fillna( "N", inplace=True)
df.loc[:,"Embarked"].fillna( "N", inplace=True)
df.loc[:,"Fare"].fillna(0, inplace=True)
# => 채울려고 하면 뭔가 기준이 있어야 한다
# + 개별적인 특성 + 모델을 통한 예측 + 유사한 데이터 대표값
return df
- fillna() : Pandas 메서드, 결측값(NaN)을 처리하기 위해 사용
구조 : DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
- value : 결측값을 대체할 값
- inplace : 변경 사항을 원본 객체에 적용할지 여부 (Ture: 원본 객체 수정)
- Step2 함수 : 모델에서 사용하지 않을 컬럼들을 제거
=> 모델의 target을 설명하기에 부적절한 변수들은 제거
이미 다른 값으로 변형을 해서 불필요한 변수들도 제거
입력 : df
기능 : 불필요한 컬럼 제거
출력 : 컬럼이 제거가 된 df
def drop_feature(df):
# -> 내가 생각하는 불필요한 컬럼들 제거
# + tree기반의 모델이 중요하다고 하는 변수 중심으로 남기고
# 나머지들을 제외를 하거나 수정해서 Feature를 변경할 수 있다.
# -> pandas에서 drop : axis =0/1
df.drop( ["PassengerId","Name","Ticket"], axis=1, inplace=True )
return df
- drop() : Pandas 메서드, 특정 행이나 열을 제거
구조 : DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
- labels : 제거할 행이나 열의 이름
- axis : 제거할 방향 (1 : 열 제거)
- inplace : 변경 사항을 원본 객체에 적용할지 여부 (True : 원본 객체 수정)
data.loc[:,"Cabin"].value_counts()
# => 너무 많은 종류가 발생을 하기에 큰 구역 정도 정보만
# => 앞에 있는 대문자 1개만 보고, 인코딩을 하자
# 기존의 컬럼의 값을 변경 앞의 구역 문자로

data.loc[:,"Cabin"].apply(lambda x : str(x)[:1]).value_counts()
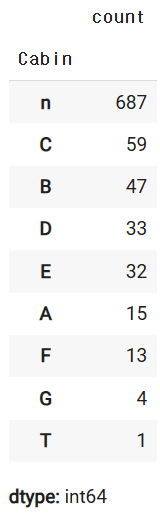
- apply(lambda x : str(x)[:1]).value_counts()
각 요소를 문자열로 변환 -> 각 문자열의 첫 번째 문자만 추출 -> 고유 값 별 빈도 계산
- Step3 함수 : 숫자가 아닌 컬럼들을 숫자로 변경 : 인코딩
=> test에서 unseen data를 고민
=> house price에서는 이 부분을 다 고려해서 전처리도 따로 처리할 예정
def encode_feature(df):
# Cabin : 개별의 종류가 147개 정도로 너무 많다.
# => EDA + 도메인 특성 : 앞글자 1개만 대표화를 하겠다
data.loc[:,"Cabin"]=data.loc[:,"Cabin"].apply(lambda x : str(x)[:1])
# 라벨인코딩
cols = ["Cabin", "Sex","Embarked"]
# + 간단하게 하기 위해서 순서 이런 것들은 무시하고, 그냥 사전순 0~~n
# + test엣의 unseen data를 고려해서 해야하는데 여기서는 skip
for col in cols:
le = LabelEncoder()
le.fit(df.loc[:,col])
# + 작년에 또 이 부분이 scikit-learn이 수정을 한다.
# => pandas 3.x : 이런 스타일로 할래요
df.isetitem( df.columns.get_loc(col), le.transform(df.loc[:,col]))
return df
- LabelEncoder().fit(df.loc[:,col])
- Pandas와 scikit-learn을 사용하여 열에 대해 Label Encoding을 수행하는 과정 중 일부
- 데이터프레임의 특정 열에 있는 고유 값을 정수로 변환하는 작업을 준비 - LabelEncoder() : scikit-learn의 클래스
- 범주형 데이터(문자열or숫자) 값을 정수로 변환 - .fit() : LabelEncoder 객체를 데이터에 맞게 학습
- df.isetitem( df.columns.get_loc(col), le.transform(df.loc[:,col]))
- Pandas와 scikit-learn의 Label Encoding으로 변환, 변환된 값을 원래 데이터 프레임의 해당 열에 다시 업데이트 - le.transform(df.loc[:, col])
- le : 이전에 학습된 LabelEncoder 객체
- .transform() 메서드 : 이미 학습된 고유 값 매핑을 사용하여 열의 값을 정수로 변환 - df.isetitem(index, value)
- Pandas에서 데이털르 특정 위치에 직접 업데이트하는 데 사용
- index는 업데이트할 열의 위치, value는 변환된 값
- 전처리에 대해서 하나의 함수 : 정리
+ 클래스( 본인 스타일 )
def titanic_preproccessing( df ):
df = check_fillna(df)
df = drop_feature(df)
df = encode_feature(df)
# ........
return df
# 변경을 할 때에는 train만 기준을 잡고, train+test에 그대로 적용
# + test에서 unseen data 코드
- check_fillna : 데이터프레임 df의 결측값(NaN)을 처리하는 함수
- drop_feature : 데이터프레임 df에서 불필요한 열(feature)을 제거하는 함수
- encode_feature : 데이터프레임 df의 범주형 열을 숫자로 변환(인코딩)하는 함수
- 일반적으로 사용되는 인코딩 방식
- Label Encoding : 범주형 데이터를 고유 정수로 변환
- One-Hot Encoding : 범주형 데이터를 다중 이진 열로 변환
data.head()

# 정답지하고 문제지를 분리 : y, X
y_titanic = data.loc[:,"Survived"]
X_titanic = data.drop("Survived", axis=1) # 성능이 엄청 잘 나옴!
X_titanic.head()
# + 앞에서 만들어둔 전처리 함수 통과
X_titanic = titanic_preproccessing(X_titanic)
X_titanic.info()
- X_titanic = titanic_preproccessing(X_titanic)
- preprocessing : 데이터를 분석 또는 모델링에 적합한 형태로 변환하는 작업
- 타이타닉 데이터셋에 대해 데이터 전처리 과정을 수행하는 함수
#출력 생략
- ML을 돌릴 수 있는 X의 모양이 만들어 진다.
=> 오로지 tree기반의 모델로만 하려고 했기에
각 변수들에 대한 정규화 작업은 생략을 했다.
추후에 개선사항으로 고려는 해볼 수 있다.
X_titanic.head()

- 아래 그림에서 빨간색까지가 위에서 train 데이터에 대한 전처리
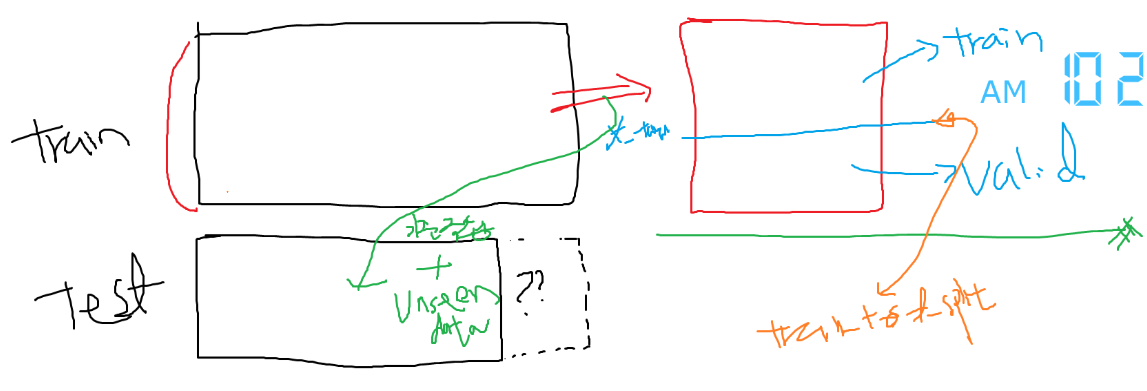
- 전처리가 된 train 데이터를 가지고 train/valid 분리
FM : train(train/valid) / test
학습에 사용되는 것( F에 있는 파라미터 최적화에 사용) : train - 학습X 오로지 평가에 사용
- valid( 내가 정답을 알고 자체 평가)
- test (kaggle 같은 경우는 내가 정답을 모르니 힘들)
-> 잘했고 못했고에 대한 부분이 : 선택/ 비교 => valid
# 데이터를 뭔가 분리를 하고자 할 때 : train_test_split 모듈
from sklearn.model_selection import train_test_split
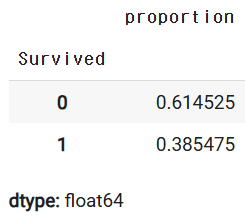
y_titanic.value_counts(normalize=True)
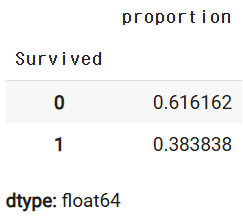
- value_counts(normalize=True)
- Pandas에서 시리즈의 고유 값별 비율(정규화된 빈도)을 계산할 때 사용하는 메서드
- normalize =True : 각 값이 전체 데이터에서 차지하는 비율로 반환
X_train, X_val, y_train, y_val = train_test_split(
X_titanic, # 처리가 된 문제지
y_titanic, # 처리가 된 정답지
test_size = 0.2, # train 중에서 얼마를 val으로 남길지
random_state=1234
)
- Scikit-learn의 train_test_split 함수를 사용하여 데이터를 학습(train)과 검증(validation) 세트로 분리하는 작업을 수행
- X_titanic : 독립 변수(특징, feature) 데이터셋
- y_titanic : 종속 변수(타겟, label) 데이터셋
- test_sizq = 0.2 : validation 20%, train 80%로 할당
- random_state=1234 : 데이터 분할을 재현 가능하게 하기 위해 난수 시드 값을 고정한다.
=> 동일한 코드 실행 시 항상 동일한 데이터 분할 결과 얻을 수 있다.

y_train.value_counts(normalize=True)
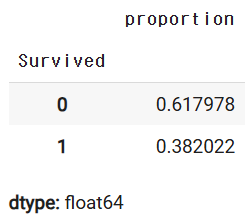
y_val.value_counts(normalize=True)
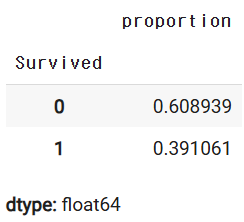
- 특정한 값을 중심으로 비율을 유지하면서 분리를 할 때
X_train, X_val, y_train, y_val = train_test_split(
X_titanic, # 처리가 된 문제지
y_titanic, # 처리가 된 정답지
test_size = 0.2, # train 중에서 얼마를 val으로 남길지 고민
random_state=1234 ,
#+ 원본의 비율을 맞춰가면서 하려고 하면 어떤 기준의 비율
stratify=y_titanic
)
y_titanic.value_counts(normalize=True)
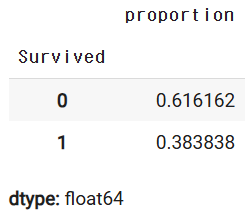
y_train.value_counts(normalize=True)
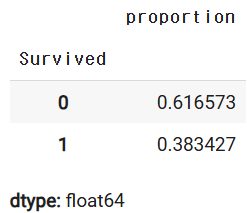
y_val.value_counts(normalize=True)
- 이제는 train 용의 데이터들을 활용하자
목적 : 일반적인 성능을 잘 나타내는 모델을 찾아보자
=> 1번 train 해서 그 결괄르 보기에는 애매하다
=> k번 (k-fold) train을 여러번 검증해보자
: 비교/평가를 위해서는 재현성이 있어야 한다
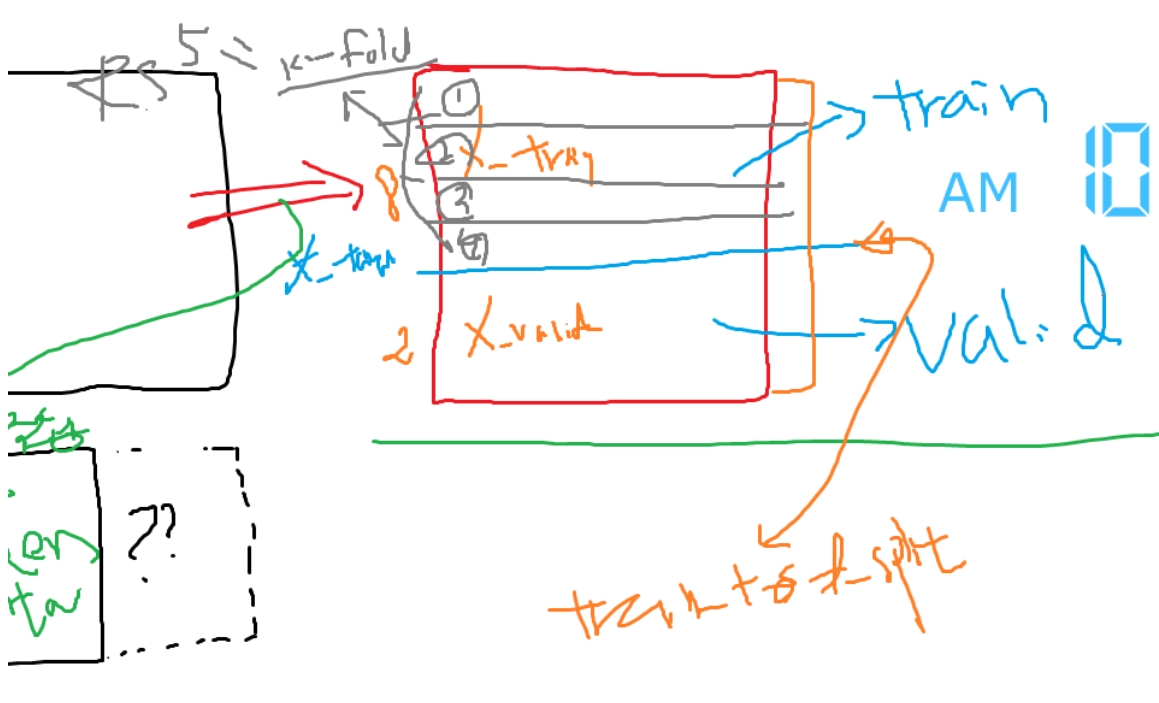
- train 데이터를 활용을 해서 HPT 비교하기 위해서는
공통된 기중/평가 셋있어야 비교가 용이하다.
=> k-fold에서 재현성을 가지고 동일한 비교 셋을 세팅
- 1) 일반적인 k-fold
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 5, random_state=1234, shuffle=True)
# cv=5 할 때마다 5셋은 맞으나 멤버가 그 때 그 때 다름
# cv=kfold 언제 어디서든 train만 동일하다면 동일한 5개 셋
# 재현
- 2) 비율을 유지하면서 k-fold
from sklearn.model_selection import StratifiedKFold
str_kfold = StratifiedKFold(n_splits = 5, random_state=1234, shuffle=True)
# -> target에 대한 비율을 보면서 5개로 샘플링을 하고 + 재현성
- cf) 데이터가 적음에도 불구하고 k-fold 방식을 하고 싶다
데이터의 수가 부족할 떄는 굳이 k-fold안 할 수 있다.
=> 그럼에도 불구하고 하겠다...데이터를 펌핑을 한 상태에서 진행
from sklearn.model_selection import RepeatedKFold
rkfold = RepeatedKFold(n_splits = 5, random_state=1234, n_repeats=10 )
from sklearn.model_selection import RepeatedStratifiedKFold
rskfold = RepeatedStratifiedKFold(n_splits = 5, random_state=1234, n_repeats=10 )
앞으로 할 일 과정
- 1) 개별 모델에 대한 대략적인 성능 체크 : BaseLine
- 2) 개별 모델에 대한 성능을 최대한 끌어올리는 작업 : HPT
- RandomGridSearch : 크게 생각한 파라미터들의 조합을 추리용도
- GridSearch : 좀 더 디테일하게 탐색
==> 효율적인 방법 중 하나 : Bayeisan OPT + GridSearchcv 같이
[ Bauseain OPT으로 큰 범위를 세팅을 해서 여러 실험을 좀 범위] - 3) 실제 모의 평가 진행 : 모델의 성능 -> Val
=> 개별 모델에 대한 성능의 최적화 잘 되었는지 체크
만약에 성능이 별로다 : 2번으로 가서 다른 동네가서 찾아서
=> 최적의 f들을 찾아가는 과정 : knn, rf, xgboost - 4) 최종 모델을 선택
4-1) 시도한 여러가지 모델 중에서 제일 best : rf -> final
4-2) 여러 모델이 있으니,,,종합해서 진행 voting 시도
Hard Voting // Soft Voting : Many + Diversity
4-3) Stacking 기타 등등등.
=> 하나의 루틴 정도, 꼭 이렇게 해야하는건 아님
큰 틀에서는 정형화되어 있지만 세부적인 기준은 스스로 결정 - 5) 최종 실전 test.csv 의 문제를 풀어서 제출
+ 기준 : train 의 데이터를 보고 처리한 기준을 그대로 "적용"
+ unseen data 있는 부분에 대한 코드 처리
모델을 학습하는 과정에서 필요한 모듈
# 1) base_line : cross_val, 통으로 학습 fit/predict 평가를 할 수도 있다
from sklearn.model_selection import cross_val_score
# 2) 평가 : 채점기 -> 출제자의 의도에 맞는 평가 방식으로 채점
# => 분류 : 정확도 accuracy를 기준으로 평가지표
# + 다양한 지표를 선택 + 없으면 직접 만들어서도
from sklearn.metrics import accuracy_score
# 3) HPT : 시간적으로 많은 소요가 되는 부분
# => sklearn : RandomGridSearchCV, GridSearchCV
# + optuna 외부 pkg 활용해서 같이 할 수 있다 (따로 이야기를)
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
- 1번 f(x)의 후보 : knn 모델
ref) 1.5.2
https://scikit-learn.org/1.5/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
KNeighborsClassifier
Gallery examples: Release Highlights for scikit-learn 0.24 Classifier comparison Plot the decision boundaries of a VotingClassifier Caching nearest neighbors Comparing Nearest Neighbors with and wi...
scikit-learn.org
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_jobs=-1)
# => 알고리즘과는 상관이 없는 기타 옵션들은 설정
scores = cross_val_score(
knn, X_train, y_train,
cv = kfold, scoring="accuracy"
)
scores
array([0.74825175, 0.69230769, 0.69014085, 0.64084507, 0.76056338])
for iter, acc in enumerate(scores):
print(f"KNN의 {iter}시도 acc:{acc}")
print(f"KNN의 평균 acc:{scores.mean()}")
print(f"KNN의 std acc:{scores.std()}")

- 주어진 데이터와 전처리에 한해서
대충 knn을 돌려보면 대략 0.7 정도에서 acc 나올 것이라 예상
( 0.64~0.76 : 편차는 좀 있을 수 있겠네) - 이제 할 일은 : knn으로 한다고 하면 더 디테일한 파라미터들을 찾아봐서
성능이 0.7보다는 좀 더 좋게 나오는 것을 찾아보자
HPT : 평균 acc가 0.7보다는 크고 편차는 좀 적게 나왔으면
- HPT 에 사용할 수 있는 수단
RGS/GS : 매번 시행이 독립적
optuna : 과거 시행의 결과를 활용해서 다음 시행을 탐색
=> 활용 - RGS -> 테스트할 파라미터들의 조합들 중에서 임의로 선택
=> sklearn일정 버전에서 변질이 되었다.
=> 큰 범위에서 찾을 때 : 배를 타고 출발할 때
- 내가 직접 테스트할 파라미터들을 세팅
parameters = {
# test할 파마미터의 값 나열 : 직접, range, math , 리스트컴프리핸션 etc
"n_neighbors" : [1,3,5,7,9,11,13,15,17,19], # 10개
"algorithm" : ["auto","ball_tree","kd_tree"] # 3개
# GS:10 * 3= 30개의 시도
# RGS : 30개 중에서 몇 개만 샘플링해서 시도
}
RGS
# 1) 사용할 모델 : HW적인 부분은 기본으로 세팅
knn = KNeighborsClassifier(n_jobs=-1)
# 2) 몇 번을 샘플링을 할지 : 테스트할 수
# => 예 : 파라미터의 조합 30개 -> 테스트할 수 : 40개 에러
n_iter = 10 # -> test할 파라미터의 조합의 수보다 크면 에러 발생
# 3) RSCV 세팅 : 모델
knn_kf_rgs = RandomizedSearchCV(
knn,
# 실험할 파라미터의 조합들을 알려줘야 함 : dict
param_distributions=parameters,
cv = kfold,
scoring="accuracy",
n_iter = n_iter,
random_state=1234, # -> 파라미터 조합에 대한 샘플링을 할 때 재현
# 병렬처리에 관련된 부분
n_jobs = -1
)
# 4) 실제 데이터를 밀어 넣어서 학습
knn_kf_rgs.fit( X_train, y_train)
)
- RGSCV의 실제 수행한 결과 : 로그표
knn_kf_rgs.cv_results_

- 했던 조합들 중에서,,제일 좋았던 조합을알려줘
-> cv 평가 기준의 평균 수치 & 제일 앞에 파라미터만 이야기를 한다.
knn_kf_rgs.best_params_
{'n_neighbors': 3, 'algorithm': 'auto'}
- 제일 성능이 좋은 평균적인 score는 얼마였나?
knn_kf_rgs.best_score_
0.7289471092287994
- train에서는 좋게 나왔지만 실제로 그럴까?
=> val으로 자체 평가 - 실험했던 결과들 중에서 제일 좋은 성능의 모델
knn_kf_rgs_best = knn_kf_rgs.best_estimator_
# -> val에 대한 문제를 풀어야 한다
knn_kf_rgs_ypred = knn_kf_rgs_best.predict(X_val)
# -> val에 대한 채점
knn_kf_rgs_acc = accuracy_score( y_val, knn_kf_rgs_ypred)
print("KNN k-fold RGS Acc:", knn_kf_rgs_acc)
KNN k-fold RGS Acc: 0.6480446927374302
- train(k-fold AVG): 0.72
val : 0.64 - OF
-> n_neightbors : 크게 조절을 해야 좀 완화가 된다.
직접 테스트할 파라미터들 세팅
parameters = {
# test할 파마미터의 값 나열 : 직접, range, math , 리스트컴프리핸션 etc
"n_neighbors" : [5,7,9,11,13,15,17,19,21,23], # 10개
"algorithm" : ["auto","ball_tree","kd_tree"] # 3개
# GS:10 * 3= 30개의 시도
# RGS : 30개 중에서 몇 개만 샘플링해서 시도
}
# RGS
# 1) 사용할 모델 : HW적인 부분은 기본으로 세팅
knn = KNeighborsClassifier(n_jobs=-1)
# 2) 몇 번을 샘플링을 할지 : 테스트할 수
# => 예 : 파라미터의 조합 30개 -> 테스트할 수 : 40개 에러
n_iter = 10 # --> test할 파라미터의 조합의 수보다 크면 에러 발생
# 3) RSCV 세팅 : 모델로 포장해준다
knn_kf_rgs = RandomizedSearchCV(
knn,
# 실험할 파라미터의 조합들을 알려줘야 함:dict
param_distributions=parameters,
cv = kfold,
scoring="accuracy",
n_iter = n_iter,
random_state=1234, # -> 파라미터 조합에 대한 샘플링을 할 때 재현
# 병령처리에 관련된 부분
n_jobs = -1
)
# 4) 실제 데이터를 밀어 넣어서 학습
knn_kf_rgs.fit( X_train,y_train)

knn_kf_rgs.best_score_
0.712075248694967
knn_kf_rgs.best_params_
{'n_neighbors': 19, 'algorithm': 'auto'}
knn_kf_rgs_best = knn_kf_rgs.best_estimator_
# -> val에 대한 문제를 풀어야 한다.
knn_kf_rgs_ypred = knn_kf_rgs_best.predict(X_val)
# -> val에 대한 채점
knn_kf_rgs_acc = accuracy_score( y_val, knn_kf_rgs_ypred)
print("KNN k-fold RGS Acc:", knn_kf_rgs_acc)
KNN k-fold RGS Acc: 0.6983240223463687
- 처음한 파라미터와 나중에 한 파라미터가 train 엇비슷
처음 결과는 OF느낌이 있다.
나중에 한 파라미터는 n값이 큰 : OF 완화가 되지 않았을까
나중 결과가 조금 더 적당히 학습한 모델
- 그러면 19주변을 좀 더 디테일하게 찾아보 GridSearchCV
knn_kf_rgs.best_params_
{'n_neighbors': 19, 'algorithm': 'auto'}
knn_kf_rgs.cv_results_

# 1.테스트할 파라미터들 세팅
parameters ={
"n_neighbors" : [19,17,21], # 3
"algorithm":["auto","ball_tree","kd_tree"] # 3
# -> GS : 3*3=9가지 경우 모두다 실험
}
# 2. 사용할 모델
knn = KNeighborsClassifier(n_jobs=-1)
# 3. 직접 모든 파라미터들을 다 해주는 GridSearchCV => 하나의 모델
knn_kf_gs = GridSearchCV(
knn,
param_grid=parameters,
cv = kfold,
scoring="accuracy",
####
n_jobs= -1
)
# 4. 실제 데이터를 넣어서 학습
knn_kf_gs.fit(X_train, y_train)

knn_kf_gs.cv_results_

- RandomSearchCV에서 찾은 k=19인 값 주변으로 찾아봐도
19가 제일 나은거 같습니다 ( 평균 중심 )
아까전에 찾은 모델이 knn에서는 제일 best구나 - F(x)의 후보 2 : RF
ref : 1.5.2
https://scikit-learn.org/1.5/modules/generated/sklearn.ensemble.RandomForestClassifier.html
from sklearn.ensemble import RandomForestClassifier
RF:baseline
rf = RandomForestClassifier( n_jobs=-1, random_state=1234)
scores = cross_val_score( rf,
X_train,y_train,
cv=kfold,scoring="accuracy")
scores
array([0.82517483, 0.83916084, 0.79577465, 0.77464789, 0.81690141])
for iter, acc in enumerate(scores):
print(f"RF의 {iter}시도 acc:{acc}")
print(f"RF의 평균 acc:{scores.mean()}")
print(f"RF의 std acc:{scores.std()}")

- RF으로 이 데이터에 대해서 모델링을 한다면
train 기준으로 대략 0.80내외가 나올 것 같다 - 할 일 : RF의 여러가지 세부적인 파라미터들을 조절하면서
0.80보다 높게 나오도록 RF최적화를 하자 HPT
len(X_train.columns) # baseline에서 8---> root(8) : 2. -->max_col=2
8
RGS
# 1. 모델
rf = RandomForestClassifier( n_jobs=-1, random_state=1234)
# 2. 테스트할 파라미터들 : dict
parameters ={
# RF : Bagging --> 여러 모델을 셋을 만들어서 여러 모델의 종합
# -> 몇 개의 모델을 활용할 것인가
# ( 너무 많으면 시간이 걸림 )
"n_estimators" : [10, 30,50,70,100,200,300,500,1000,2000],
# => many : col 어떻게 구성할지 + Diversity
"max_features" : [ 3,4,5,6,7],
# 개별 데이터셋에 대한 개별 모델 : DT -> OF
"max_depth": [2,3,4,5,6,7,8,10,20],
"min_samples_split": [1,3,5,7,9]
# => 개별 DT의 OF을 조절하려는 파라미터들이다.
# Bias를 좀 손해보더라도 Variance 확보 : New 일반성
}
# 3. RGS -> 대충 어느 범위가 괜찮을지
n_iter = 20
rf_kf_rgs = RandomizedSearchCV(
rf,
param_distributions=parameters,
cv = kfold,
n_iter = n_iter,
random_state =1234,
scoring="accuracy",
n_jobs=-1
)
# 4. 실제 데이터 넣어서 학습
rf_kf_rgs.fit(X_train, y_train)
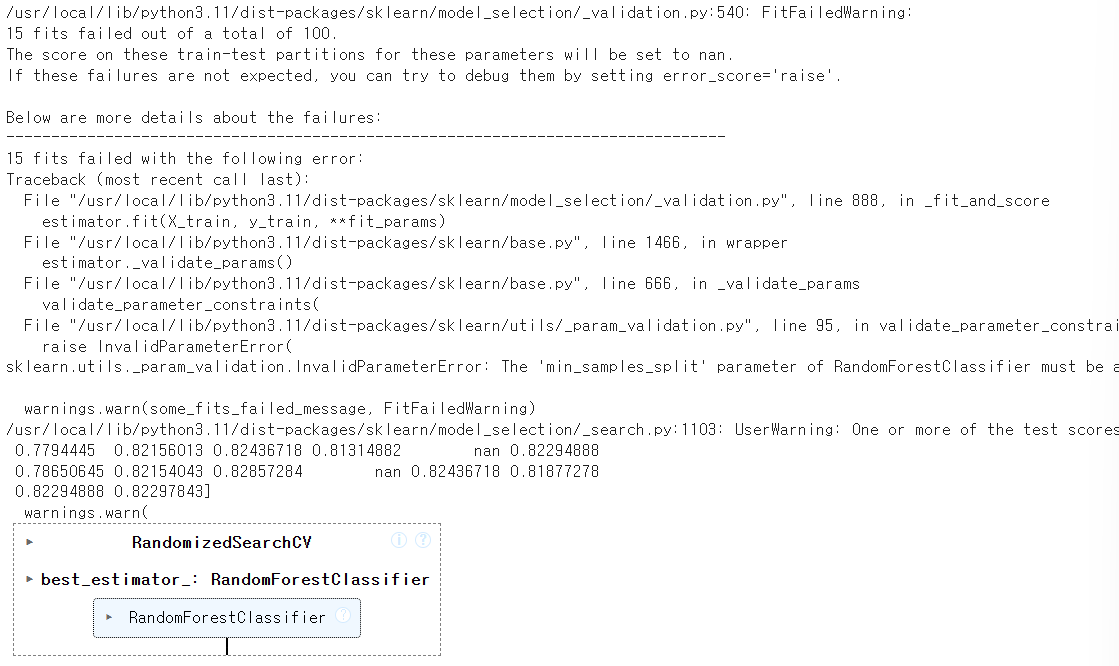
- 내가 실험을 하려고 한 파라미터들이 데이터의 특성과 안 맞아서
에러나 경고, 수렴이 안 되는 경우들이 나올 수 있다.
rf_kf_rgs.cv_results_
#출력 생략
rf_kf_rgs.best_score_
0.828612232837585
rf_kf_rgs.best_params_
{'n_estimators': 70, 'min_samples_split': 5, 'max_features': 7, 'max_depth': 4}
RGS 의 모의 성능평가
rf_kf_rgs_best = rf_kf_rgs.best_estimator_
rf_kf_rgs_ypred = rf_kf_rgs_best.predict(X_val)
rf_kf_rgs_acc = accuracy_score(y_val, rf_kf_rgs_ypred)
rf_kf_rgs_acc
0.8268156424581006
X_val.shape
(179, 8)
- RGS로 찾은 파라미터 주변에 더 좋은 값은 없을까?
GS
rf_kf_rgs.best_params_
{'n_estimators': 70, 'min_samples_split': 5, 'max_features': 7, 'max_depth': 4}
- GS : 위의 파라미터 주변으로 좀 더 디테일하게 찾아볼까
rf = RandomForestClassifier(n_jobs=-1, random_state=1234)
parameters = {
"n_estimators": [70, 50, 100,500],
"max_features" :[7,6,5],
"max_depth" :[3,4,5],
#"min_samples_split":[4,5,6] # -> 시간이 너무 걸려서 주석처
# => 4*3*3*3 = 27*4 = 1XX * cv5 = 5XX
}
rf_kf_gs = GridSearchCV(
rf, param_grid=parameters,
cv=kfold, scoring="accuracy",
n_jobs=-1
)
rf_kf_gs.fit(X_train,y_train)

rf_kf_gs.best_score_
0.8300206835418104
rf_kf_gs.best_params_
{'max_depth': 4, 'max_features': 7, 'n_estimators': 70}
- val에 대해서 평가
rf_kf_gs_best = rf_kf_gs.best_estimator_
rf_kf_gs_ypred = rf_kf_gs_best.predict(X_val)
rf_kf_gs_acc = accuracy_score(y_val, rf_kf_gs_ypred)
rf_kf_gs_acc
0.8268156424581006
- RGS : 0.828612232837585 --> 0.8268156424581006
GS : 0.8300206835418104 --> 0.8268156424581006 - 둘 중 어떤 것이 더 성능이 좋을걸까?
정답은 없다=> 스스로 선택을 하시면 됩니다
본인이 왜 그렇게 의사 결정을 했는지가
- 팀 프로젝트 하다보면
역할별로, 맡은 모델별로 최적활르 하고 공유
=> 내가 만든 모델에 대해서 저장 & 불러오는 과정
model_save, model_load : DL - anaconda에 대표적으로 joblib
import joblib
- 1. 모델을 저장 : joblib.dump( 어떤 모델, 어디다 저장할지)
=> 파이썬 계열에서는 주로 모델을 저장할 때 파일 양식 : pickle / .pkl
+ 모델이 큰 경우에는 몇 백메가, 몇 십 기가, 몇 백 기가
joblib.dump(rf_kf_gs_best, "rf_kf_best.pkl" )
['rf_kf_best.pkl']
- 2. 받은 모델을 불러와서 사용하자 : joblib.load(불러올모델경로)
model_path = '/content/rf_kf_best.pkl'
rf_backup = joblib.load(model_path)
rf_backup

- 간단하게 불러온 것이 동일한 체크
(rf_kf_gs_best.predict(X_val) != rf_backup.predict(X_val)).sum()
0
참고) 조원분들이 각기 머신들을 사용하면서 진행
- OS에 발생을 하는 경우에는 에러가 발생을 한다.
- check1. scikit-learn 의 버전을 맞춰야 한다.
: 혹 버전이 조금이라도 안 맞으면 에러 발생 - check2. 명확하게 pickle 패키지를 불러서 사용해야 한다
:joblib 패키지가 아니라 pickle 근본 패키지를 불러서 사용하자 - check3. 파일을 입출력을 할 때 : Open()메서드로 활용
- OS가 다른 상황으로 가정
import pickle
file_name = "my_model.pkl"
pickle.dump( rf_kf_gs_best, open(file_name, "wb"))
- OS가 다른 상황에서 불러올때
import pickle
model_path = '/content/my_model.pkl'
new_model = pickle.load( open(model_path, "rb"))
new_model

F(x) 3번째 : xgboost
- 지금 : colab에서 충돌이 있다
본인 노트북에서 하려고 하면 따로 설치 : https://anaconda.org/conda-forge/xgboost
colab에서는 이미 설치가 되어 있다
+ GPU를 사용할 수 있다 ( 나중에 설명 )
ref : https://xgboost.readthedocs.io/en/stable/ - xgboost - scikit api
https://xgboost.readthedocs.io/en/stable/python/python_api.html#module-xgboost.sklearn
from xgboost import XGBClassifier
baseline
xgbc = XGBClassifier(n_jobs=-1, random_state=1234)
scores = cross_val_score( xgbc, X_train,y_train,
cv=kfold, scoring="accuracy")
scores
array([0.83916084, 0.86013986, 0.78169014, 0.8028169 , 0.82394366])
scores.mean()
0.8215502807052102
- xgboost로 대략 0.82 acc -> 이상은 나와야 하지 않을까
- 참고) boosting 계열 알고리즘 : 중요한 파라미터를 제외하고는
세부 파라미터에 대한 조절에 의한 값의 변화가 크지 않다.
=> 주된 파라미터들을 제외하고는 튜닝에 대한 가성비가 낮다
( 너무 힘을 빼지는 마세요)
=> 부스팅 계열은 주된 파라미터 중심으로 체크
- RGS 수행
xgbc = XGBClassifier(n_jobs=-1, random_state=1234)
# 테스트할 파라미터
parameters = {
# 일반적인 부스팅과 관련된 주된 파라미터 : 몇 개의 모델을 many + learning_rate/eta
"n_estimators" : [10,30,50,100,300,500],
"learning_rate" : [0.01, 0.1, 0.2, 0.3],
# 개별 모델에 대한 조절 : tree 모형 -> OF 조절
# 인위적으로 트리를 조절
"max_depth":[2,3,4,5,6,10],
# 더 분화를 할지에 대한 기준 값
"gamma" : [0.1, 0.2, 0.3],
# etc : 개별 tree에 대한 OF을 조절하는 파라미터들
# GBM 기본적으로 OF이 심한 모델
# => 샘플링을 가로, 세로 : RF의 max_feature + max_sample
"subsample" : [0.3, 0.4, 0.5, 0.6, 0.9], # 가로에 대한 비율
"colsample_bytree" : [0.3, 0.4, 0.5, 0.6, 0.9 ], # 세로에 대한 비율
# + opt
# => 규약에 대한 조건
# reg_alpha, reg_lambda : 논문을 보고 선형회귀쪽
}
n_iter = 10 # 원래는 이 정도의 조합이면 엄청 더 시도를 해야하는데
# 시간 관계상 줄이는 것일 뿐
xgbc_kf_rgs = RandomizedSearchCV(
xgbc,
param_distributions=parameters,
cv = kfold,
scoring="accuracy",
n_iter= n_iter,
random_state=1234,
n_jobs=-1
)
xgbc_kf_rgs.fit(X_train, y_train)

xgbc_kf_rgs.cv_results_
#출력 생략
xgbc_kf_rgs.best_params_

xgbc_kf_rgs.best_score_
0.8271840835221116
- 자체평가
xgbc_kf_best = xgbc_kf_rgs.best_estimator_
xgbc_kf_ypred = xgbc_kf_best.predict(X_val)
xgbc_kf_acc = accuracy_score(y_val,xgbc_kf_ypred )
xgbc_kf_acc
0.8044692737430168
- train : 0.827 -> val : 0.804
- -> 주변을 좀 찾아보면 조금 더 나아지지 않을까?
GS
xgbc_kf_rgs.best_params_

parameters= {
"subsample": [0.4, 0.3],
"n_estimators":[300,250,500],
"max_depth":[2,3],
"learning_rate":[0.01, 0.005, 0.02],
"gamma" : [0.2, 0.15, 0.25],
"colsample_bytree":[0.6, 0.5]
} # --> 2 * 3 * 2* 3* 3* 2
xgbc = XGBClassifier(n_jobs=-1, random_state=1234)
xgb_kf_gs = GridSearchCV(
xgbc,
param_grid=parameters,
cv=kfold,
scoring="accuracy",
n_jobs=-1 # verbose 파라미터를 사용하면 중간 결과들을 모니터링
)
xgb_kf_gs.fit(X_train,y_train)

xgb_kf_gs.best_score_
# train : 0.827 -> val : 0.804
0.8342361863488623
xgb_kf_gs_best = xgb_kf_gs.best_estimator_
xgb_kf_gs_ypred = xgb_kf_gs_best.predict(X_val)
xgb_kf_gs_acc = accuracy_score(y_val, xgb_kf_gs_ypred)
xgb_kf_gs_acc
0.8044692737430168
- train : 0.827 ---> val : 0.804 ( RGS )
train : 0.834 ---> val : 0.804 ( GS )
- 오늘한 이 과정들은 여러분들 프로젝트 하시는 과정과 거의 동일
- 오늘한 기본적인 과정은 잘 파악을 해야 함 => 코드랑 그림
쉬었다가 조별 플젝 진행
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 35일차 (25.01.23) (0) | 2025.01.23 |
|---|---|
| ASAC 빅데이터 분석가 과정 34일차 (25.01.22) (0) | 2025.01.22 |
| ASAC 빅데이터 분석가 과정 32일차 (25.01.20) (0) | 2025.01.20 |
| ASAC 빅데이터 분석가 과정 31일차 (25.01.17) (0) | 2025.01.17 |
| ASAC 빅데이터 분석가 과정 30일차 (25.01.16) (0) | 2025.01.16 |