clf_main 복습
1_clf
F(X) 4번째 후보 : lightGBM
- xgboost하고 태생은 동일하다. 다만, 처리하는 방식이 조금 달라서 다른 모델로 있는 것
xgboost 보다 속도가 빠른 경향 - 개인의견 : gbm계열에서 빠르게 대충 성능을 체크하고 싶다. 먼저 사용해볼만한 모델
=> xgboost 직접 설치해야 하는 외부 패키지 ( 코랩은 이미 설치가 되어 있다. - ref) https://lightgbm.readthedocs.io/en/v4.5.0/pythonapi/lightgbm.LGBMClassifier.html#lightgbm.LGBMClassifier
from lightgbm import LGBMClassifier
- 참고) 개인적인 의견 + 상황에 따라서는 다를 수 있다.
=> 대략적인 성능 + 어떤 변수들이 중요한지 : RF/lightGBM => Tree
: n은 좀 줄여서 사용을 했다.
+ 중요한 변수들이 나오고, 대충 성능의 레벨을 체크할 수 있으므로
EDA를 먼저 수행을 하거나, 탐색을 진행을 해야한다.
baseline
- lgmc = LGBMClassifier( n_jobs=-1, random_state=1234)
scores = cross_val_score(lgmc, X_train, y_train,
cv=kfold, scoring="accuracy")
scores
# 출력 생략
- lightgbm에서는 코드 상에서 데이터가 적거나 세팅이 안 맞으면
더이상 분화를 할 수 없다고 경고문이 나올 뿐이다.
전혀 성능과 무관한 내용
scores
0.814586821629075
- HPT
lgmc = LGBMClassifier(n_jobs=-1, random_state=1234)
parameters ={
# 부스팅 관련된 주된 파라미터
# 1) 몇 개의 모델을 사용할지
"n_estimators":[10,30,50,100,300,500],
# 2) 어느 정도의 비율로 반영할지 lr
"learning_rate":[0.01, 0.03, 0.05, 0.1, 0.3],
# 개별 모델 : tree -> overfit
"max_depth" : [2,3,4],
"min_split_gain":[0.1, 0.2], # -> xgboost에서 gamma와 유사한 기능
# 샘플링
"subsample":[0.3, 0.5, 0.7, 0.9],
"colsample_bytree":[0.3, 0.5, 0.7, 0.9]
# 기타 : 규약 : 아주 메인은 아니지만 성능의 영향은 좀 준다.
}
n_iter = 10
lgmc_kf_rgs = RandomizedSearchCV(
lgmc,
param_distributions = parameters,
cv = kfold,
n_iter = n_iter,
scoring="accuracy",
n_jobs=-1,
random_state=1234
)
lgmc_kf_rgs.fit(X_train, y_train)
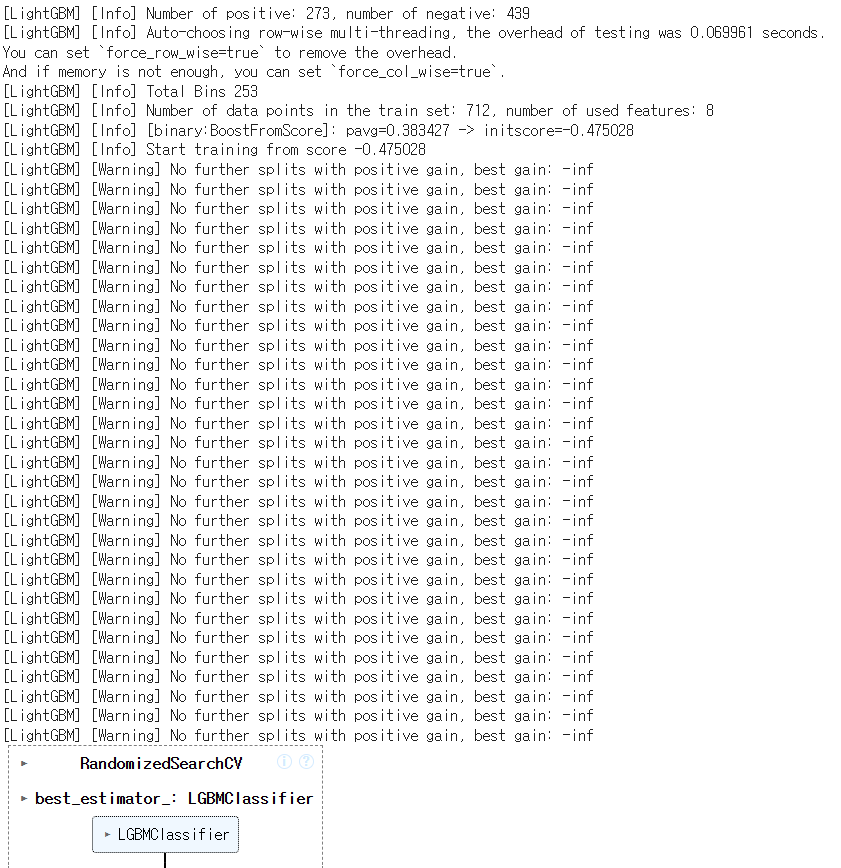
lgmc_kf_rgs.best_score_
0.8370136905348173
lgmc_kf_rgs.best_params_

lgmc_kf_rgs_best = lgmc_kf_rgs.best_estimator_
lgmc_kf_rgs_ypred = lgmc_kf_rgs_best.predict(X_val)
lgmc_kf_rgs_acc = accuracy_score(y_val, lgmc_kf_rgs_ypred)
lgmc_kf_rgs_acc
0.8324022346368715
- -> lgbm : 0.837 -> val : 0.832
- => GridsearchCV는 저는 생략
여러분들은 해보세요 (과제 예정) - 최종 모델을 선택
knn : 0.7~ #0.7X
RF : 0.8~
xgboost : 0.82~
lightgbm : 0.82~
- 결론1) 한 것들 중에서 제일 성능이 좋다고 생각하는 하나의 모델을 선택
=> lightGBM을 실험 한 것들 중에서 제일 좋다고 생각을 합니다
(train-val의 차가 적어서 5번실험에 대해서 평균 대표값)
=> test.csv 파일을 풀어서 제출 - + 잠시) 일단 만들어둔 모델들이 있으니 한 번 쥐어짜내볼까
=> Try : Voting
1) 직접 다수결을 판단하는 보팅 함수를 만들어서 하는 경우도 있다.
2) scikit-learn 있는 함수를 가져다가 사용
from sklearn.ensemble import VotingClassifier
- 1인 1표 : Hard Voting
hard_clf = VotingClassifier(
# 어떤 모델들을 가지고 다수결을 할지 : 튜플로 개별 모델 -> 리스트로
estimators = [
("RF", rf_kf_gs_best),
("XGB",xgb_kf_gs_best),
("LGBM",lgmc_kf_rgs_best)
],
# 어떤 방식으로 의견을 종합을 할지
voting="hard",
n_jobs=-1
)
hard_clf.fit(X_train, y_train)
hard_clf_ypred = hard_clf.predict(X_val)
hard_clf_acc = accuracy_score(y_val, hard_clf_ypred)
hard_clf_acc
0.8324022346368715
- 0.8324022346368715 : lgbm
0.8324022346368715 : Hard_voting -> RF/Xg/LGBM
- 1인 다표 : Soft Voting
-> GBM계열이니까 xg / lightGBM 중에서 1만 => lightGBM
RF
=> RF & lightGBM => 가중치 1: 2로 부여를 하고자 한다.
soft_clf = VotingClassifier(
# 어떤 모델들을 가지고 다수결을 할지 : 튜플로 개별 모델 -> 리스트로
estimators = [
("RF", rf_kf_gs_best),
("LGBM",lgmc_kf_rgs_best)
],
# 어떤 방식으로 의견을 종합을 할지
voting="soft",
# + 지분율을 설정
weights = [1, 2],
n_jobs=-1
)
soft_clf.fit(X_train, y_train)
soft_clf_ypred = hard_clf.predict(X_val)
soft_clf_acc = accuracy_score(y_val, soft_clf_ypred)
soft_clf_acc
0.8324022346368715
- 0.8324022346368715 : lgbm ( y_f1)
0.8324022346368715 : Hard_voting -> RF/Xg/LGBM ( y_f2)
0.8324022346368715 : Soft voting -> RF/ LGBM ( y_f3)
2_HPT
- 목적 : HPT 좀 효율적으로 해볼까
=> 또 하나의 도구 : 베이지안 최적화 ( 여러 패키지 )
이유 : "시각화"가 제공을 하기에 튜닝에 용이하기 -> optuna - 미리 설치가 되어있어야 하는 패키지 : plotly
=> 개인 pc 나 클라우드에 설치를 해야 사용이 가능함 - 참고) colba은 plotly가 이미 설치가 되어 있음
=> optuna만 설치하면 됨
!pip install optuna
# https://optuna.org
#출력 생략
import optuna
- optuna를 기본적을 사용하는 방법
=> 목적함수 세팅 : 직접 만들어야 한다. 직접 상황에 맞춰서 할 수 있어야 한다.
=> 기본 입력 : 어떻게 실행을 할지에 세팅도 직접 - 목적 함수에 대한 작성 스스로 해야 한다.
입력 : 시도
출력 : 목적 함수를 세팅
def objective(trial):
x = trial.suggest_float('x', -10, 10) # -> 시도 : 어떤 실험을 할지
return (x - 2) ** 2
# 어떻게 학습을 할지에 대해서 직접 세팅
study = optuna.create_study()
study.optimize(objective, n_trials=100)
# => 100번의 시도를 통해서 목적함수의 최적화
study.best_params # E.g. {'x': 2.002108042}
#출력 생략
- 참고) optuna에서 시도할 파라미터에 대한세팅
=> Titanic데이터에서 모델은 RF
!gdown 1Kcc5aR3ZYK8onDhQ6L-JqEyOj3BEuQoL
#출력 생략
- 기본 패키지
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
- 수집한 데이터 or 처리해야할 데이터 or 서버에서 sql로 불러온 데이터.
path = '/content/train.csv'
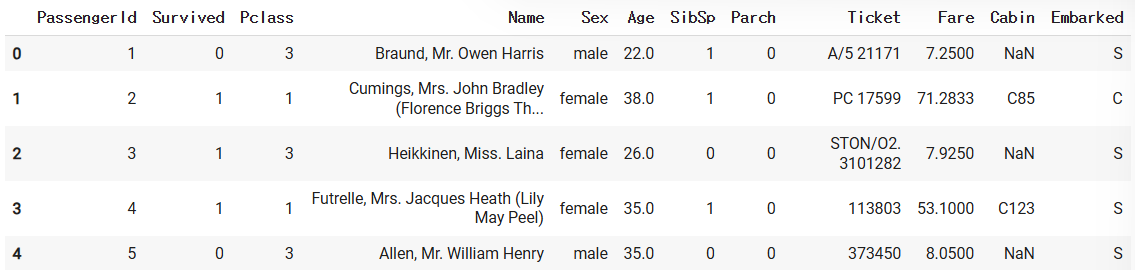
data = pd.read_csv(path)
data.head()
- Step1 함수 : 누락된 데이터를 처리
컬럼 : age, cabin, embarked, fare
입력 : df
출력 : 위의 4개 컬럼에 대한 결측치 처리해서, df로 출력
=> 필요에 따라서 수정해서 사용하시면 된다.
def check_fillna(df):
# 목적 : 누락된 값 채우자
# => 분석자가 스스로 결정!! 왜 그런 결정을 했는지 이유
df.loc[:,"Age"].fillna(df.loc[:,"Age"].mean(), inplace=True )
# => train데이터의 Age의 평균이 기준
# 엄밀하게 하기위해서는 train의 Age 평균을 test에서 Age누락된 값에 채워
# test의 Age의 평균으로 test의 Age 결측값을 채우면?
# cabin/embarked/fare 채워보자
# => 정보 없음의 값 : N,N,0
df.loc[:,"Cabin"].fillna( "N", inplace=True)
df.loc[:,"Embarked"].fillna( "N", inplace=True)
df.loc[:,"Fare"].fillna(0, inplace=True)
# => 채울려고 하면 뭔가 기준이 있어야 한다.
# + 개별적인 특성 + 모델을 통한 예측 + 유사한 데이터 대표값
return df
- Step2 함수 : 모델에서 사용하지 않을 컬럼들을 제거
=> 모델의 target,을 설명하기에 부적절한 변수들은 제거
이미 다른 값으로 변형을 해서 불필요한 변수들도 제거
입력 : df
기능 : 불필요한 컬럼 제거
출력 : 컬럼이 제거가 된 df
def drop_feature(df):
# -> 내가 생각하는 불필요한 컬럼들 제거
# + tree기반의 모델이 중요하다고 하는 변수 중심으로 남기고
# 나머지들을 제외를 하거나 수정해서 Feature를 변경할 수 있다.
# -> pandas에서 drop : axis =0/1
df.drop( ["PassengerId","Name","Ticket"], axis=1, inplace=True )
return df
- Step3 함수 : 숫자가 아닌 컬럼들을 숫자로 변경 : 인코딩
=> *** test에서 unseen data를 고민***
=> house price에서는 이 부분을 다 고려해서 전처리도 따로 처리할 예정
def encode_feature(df):
# Cabin : 개별의 종류가 147개 정도로 너무 많아요
# => EDA + 도메인 특성 : 앞글자 1개만 대표화를 하겠다
data.loc[:,"Cabin"]=data.loc[:,"Cabin"].apply(lambda x : str(x)[:1])
# 라벨인코딩
cols = ["Cabin", "Sex","Embarked"]
# + 간단하게 하기 위해서 순서 이런 것들은 무시하고, 그냥 사전순 0~~n
# + test엣의 unseen data를 고려해서 해야하는데 여기서는 skip
for col in cols:
le = LabelEncoder()
le.fit(df.loc[:,col])
# + 작년에 또 이 부분이 scikit-learn이 수정을 한다.
# => pandas 3.x : 이런 스타일로 할래요
df.isetitem( df.columns.get_loc(col), le.transform(df.loc[:,col]))
return df
- 전처리에 대해서 하나의 함수 : 정리
+ 클래스( 본인 스타일 )
def titanic_preproccessing( df ):
df = check_fillna(df)
df = drop_feature(df)
df = encode_feature(df)
# ........
return df
# *변경을 할 때에는 train만 기준을 잡고 train+test에 그대로 적용
# + test에서 unseen data!!코드
- 정답지하고 문제지를 분리 : y, X
y_titanic = data.loc[:,"Survived"]
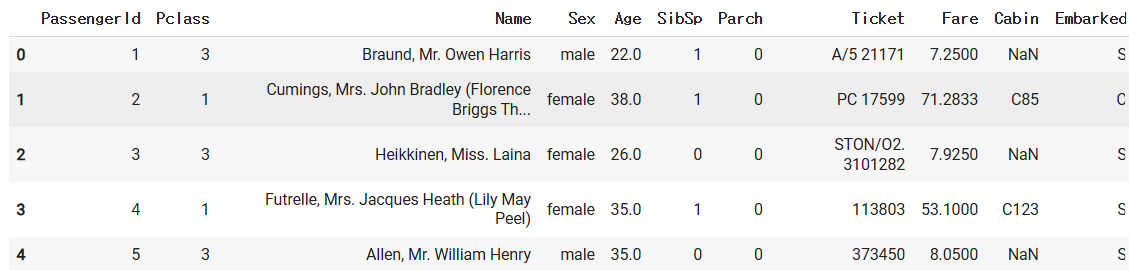
X_titanic = data.drop("Survived", axis=1) # 성능이 엄청 잘 나
X_titanic.head()
- + 앞에서 만들어둔 전처리 함수 통과
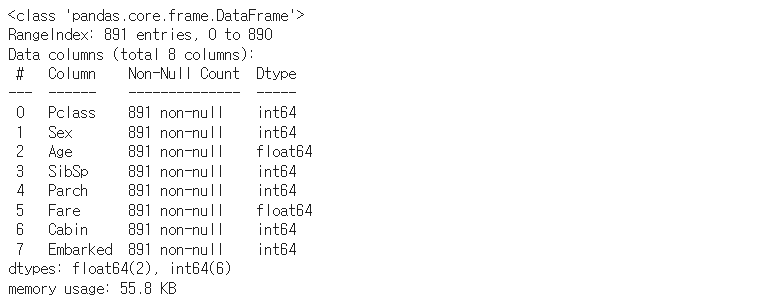
X_titanic = titanic_preproccessing(X_titanic)
X_titanic.info()
- 특정한 값을 중심으로 비율을 유지하면서 분리를 할 때
X_train, X_val, y_train, y_val = train_test_split(
X_titanic, # 처리가 된 문제지
y_titanic, # 처리가 된 정답지
test_size = 0.2, # train 중에서 얼마를 val으로 남길지
random_state=1234 ,
# + 원본의 비율을 맞춰가면서 하려고 하면 어떤 기준의 비율
stratify=y_titanic
)
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 5, random_state=1234, shuffle=True)
RF의 HFT
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
RF:baseline
rf = RandomForestClassifier( n_jobs=-1, random_state=1234)
scores = cross_val_score( rf,
X_train,y_train,
cv=kfold,scoring="accuracy")
scores
array([0.82517483, 0.83916084, 0.79577465, 0.77464789, 0.81690141])
for iter, acc in enumerate(scores):
print(f"RF의 {iter}시도 acc:{acc}")
print(f"RF의 평균 acc:{scores.mean()}")
print(f"RF의 std acc:{scores.std()}")

- 이 다음에 RF의 최적의 파라미터를 찾기 위해서는
전에 수업에서는 RGS -> GS : 최적의 모델을 튜닝을 하는 과정 - 이번에는 optuna -> GS : 최적의 모델을 튜닝을 하는 과정
=> optuna 가 ML에서만 사용하는 것이 아니라 DL에서도 가능
- optuna : 스스로 직접 목적 함수를 세팅
=> 정답은 없는데 본인 목적에 맞춰서 스스로 할 수 있어야 한다.
입력 : 1번의 개별 시도(trail) -> 무엇을 해서
출력 : 무엇을 타켓으로 최적화를 할지
def rf_objective( trail ):
# 1) Test할 파라미터들에 대한 가변적인 범위 설정 => 처음 할 때 범위를 크게
params = {
"n_estimators": trail.suggest_int("n_estimators", 10, 10000),
"criterion" : trail.suggest_categorical("criterion",["gini","entropy","log_loss"] ),
"max_features":trail.suggest_int("max_features",1, X_train.shape[1] ),
"max_depth" : trail.suggest_int("max_depth", 1, 50),
"min_samples_split":trail.suggest_int("min_samples_split", 3, 10)
}
# 2) 1번 세팅을 한 파라미터에 대한 것을 받을 함수
# => 직접 넘겨서 작성
rf = RandomForestClassifier(n_jobs=-1, random_state=1234,**params)
# --> 제안 받은 파라미터의 값들을 직접 모델에 세팅
# 3) 개취 : 통으로 학습을 하고, 평가 CV
# 3-1) 한 번 통 학습
# rf.fit(X_train, y_train)
# 3-2)CV를 사용해서 하겠다
scores = cross_val_score(rf, X_train, y_train, cv=kfold,
scoring="accuracy")
# => 5번에 대한 시도 결과 acc : 저는 개취 5번 시도의 평균 기준
acc_mean = scores.mean()
# 4) 너의 최종적으로 최적화를 하려는 대상
return acc_mean
- 위의 목적함수를 RF로 어떻게 가려는지 지향점을 설계
=> 위의 목적함수를 어떤 방식으로 학습할지에 대한 세팅
예) 목적함수 에러 타겟 : 학습의 방향 min - 목적함수 성능/정확도 타켓 : 학습의 방향 max
=> 본인 설계에 따른 방향성을 정확히 인지
rf_study = optuna.create_study(direction="maximize")
# 실제 찾아가는 과정 : 50 -> 60분 정도
rf_study.optimize(rf_objective, n_trials=60, n_jobs=-1 ) #(나는 50으로 돌림)
# 참고) 위의 방식대로 하면 재현성이 없다.
# 혹시 재현성이 중요하다고 생각을 하시면 TPESampler
#from optuna.samplers import TPESampler
#rf_study = optuna.create_study(direction="maximize", sampler =TPESampler(seed=1234) )
#출력 생략
#매우 오래 걸림!!!(GPU필요)
- 참고 : 50~60번 범위에 비해서는 적은 편이기는 하다.
=> colab에서는 core =2 ,n_jobs=-1해도 느린 편
클라우드에서 해야 한다. core 많은 것을 세팅을 해야 한다.
- 시도를 한 50~60번 결과들 중에서 목적함수 k-fold --> acc --> mean : 최고값
rf_study.best_trial.values
[0.835605239830592]
- 시도를 한 50~60번 중에서 목적함수를 최대화를 한 시도 중에서 파라미터
rf_study.best_params

- => 할 때 마다 다르게 결과가 나타날 수 있다.
- 시각화1) 시각적인 부분 optuna 특징
=> plotly 동적인 시각화 패키지를 중심
optuna.visualization.plot_optimization_history( rf_study )
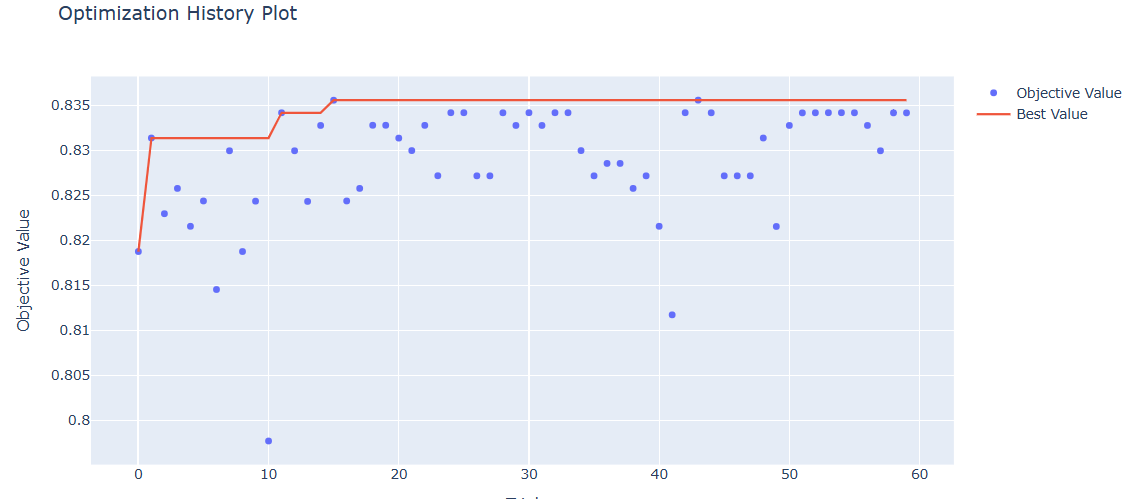
- 시각화2) 중요한 파라미터들의 시각화
optuna.visualization.plot_parallel_coordinate(rf_study)
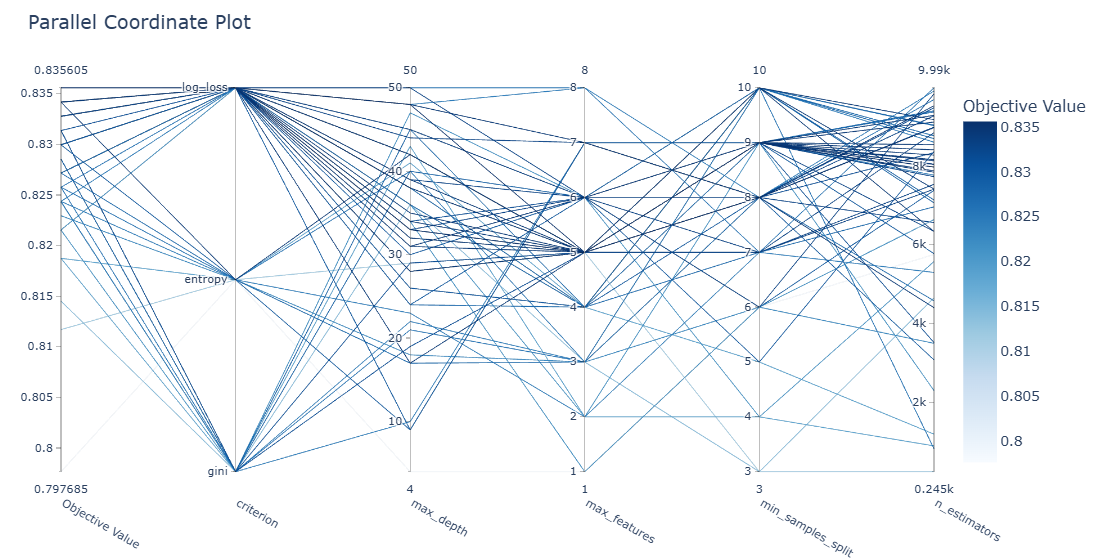
- 시각화3) Traget에 영향을 미친 주된 파라미터
optuna.visualization.plot_param_importances(rf_study)

- 참고) 이 값을 가지고 scikit-learn에서 gridsearchCV를 통해서
조금 더 실험을 진행해서 더 좋은 모델을 탐색할 수도 있다.
=> gridsearchCV하면서 제일 좋은 모델을 가져올 수 있다. - 참고) optuna에서 끝을 보려고 한다면 제일 좋은 파라미터 조합에 대한
모델을 "직접 다시 학습"을 해야 한다.
rf_study.best_params # => dict

opt_rf = RandomForestClassifier(n_jobs=-1, random_state=1234,
**rf_study.best_params)
# => 크롤링을 할 때 kobis api : json -> dict -> 통으로 넘길 때
# + 개인적으로 CV하셔도 되고 통으로 fit 하셔도 상관은 없다. 선택
opt_rf.fit(X_train, y_train)
# val 평가
accuracy_score(y_val, opt_rf.predict(X_val))
0.8268156424581006
- 참고)
Tree 기반의 모든 모델들은 가지는 장점 : 중요한 변수를 파악
단, 평가지표& 모델 기준
opt_rf.feature_importances_
array([0.0918109 , 0.27483137, 0.20514814, 0.03950191, 0.02741016, 0.24371674, 0.08021909, 0.0373617 ])
X_train.info()

- 입력 데이터의 특징의 RF입장(사용한 Tree모형의 입장에서) 중요도 시각적
import matplotlib.pyplot as plt
plt.barh(X_train.columns,opt_rf.feature_importances_ )

- 정렬을 해서 그릴려고 하
import pandas as pd
temp = pd.DataFrame(
{
"FI":opt_rf.feature_importances_
},
index = list(X_train.columns)
)
temp.sort_values(by="FI").plot(kind="barh")
- optuna 는 직접 본인이 만들어 보세요
=> 과제를 드릴테니 남의 코드를 ctrl_c/v : 직접 메뉴얼 보면서
해보는 것을 추천을 한다. - 래서 나는 어떻게 하라고?
=> 기준을 알려주세요?
본인이 알아서 판단하세요
둥리뭉실한 답변을 드릴 수 밖에 없다
* 어떤 이유로 어떻게 했다 본인의 기준 + 타당한 논리
+ 전반적인 내용들이 파악이 되야 한다. - + 내일 : 회귀 + 규약 + 코드 ( test : unseen data )
-> 전처리가 좀 복잡하다
- 과제
- 조별 플젝
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 36일차 (25.01.24) (0) | 2025.01.24 |
|---|---|
| ASAC 빅데이터 분석가 과정 35일차 (25.01.23) (0) | 2025.01.23 |
| ASAC 빅데이터 분석가 과정 33일차 (25.01.21) (0) | 2025.01.21 |
| ASAC 빅데이터 분석가 과정 32일차 (25.01.20) (0) | 2025.01.20 |
| ASAC 빅데이터 분석가 과정 31일차 (25.01.17) (0) | 2025.01.17 |