02_pandas_1d_Series
# pandas 가 앞으로 할 메인이 패키지!!!!=>데이터 핸들링!!!!
- 파이썬을 기반으로 외부에서 만든 패키지!!!!
- pandas 기본적으로 필요한 자료형 : Series, DataFrame, Pannel
===> 1차원을 처리할 자료형 : Series
2차원을 처리할 자료형 : DataFrame
3차원을 처리할 자료형 : Pannel
===> 내가 처리할 자료들이 어떤 차원의 자료형인지 명시!!!!
일반적으로 주로 2차원 2d ==> DataFrame
cf) 엑셀 통합파일 : 3차원--> pannel
엑셀 통합파일 내의 sheet :2차원 --> DataFrame
엑셀 통합파일 내의 Sheet의 1줄 : 1차원 --> Series
# 1D 표현하는 자료형 : Series
-=-> 직접적으로 사용할 일은 거의 없음!!!!
-->기능적으로 거의 유사함!!!차원만 확장이 되었다는점!!!
import numpy as np
import pandas as pd
# 기본적으로 여러개의 값들을 다루는 자료형 중 하나임!!!
쌩 파이썬의 대표 : 리스트 //튜플, dict etc,,,,
--> version up : numpy의 array 자료형( 벡터연산!!!) // 수치연산
--> version up : pandas ( 수치연산 이외에 다양한 자료형...)
# pandas를 개발한 사람들은 "차원"을 중심으로 여러 자료형!!!
1차원 : 1차원 벡터 --> Series Type
2차원 : 2차원 Matirx --> DataFrame Type **** 주로 사용하는 친구 ML **
3차원 : 3차원 tensor --> Pannel Type
--> 그 이상의 고차원은 안 함!!!!
그 이상의 고차원(비정형데이터) : TF/PyTorch DL중심!!!
+ 특징 : 인덱스를 내가 원하는 대로 만들자!!!
원하는 정보로도 내가 접근을 해보자!!!#
==> "인덱스"내가 만든 것도 있고,
"인덱스"가 태생적인 정수쪽/여러개,,기존 인덱스!!!!
# pandas의 개발 히스토리
파이썬으로 가지고 금융 데이터를 처리하고 싶었다!!!
언제, 얼마--> 장이 안 열리는 날도 존재함!!휴일....
날짜중심을 찾고자 하면,,,,,내가 원하는 날짜가 몇 번째 존재하냐!!!
2024-12-01
2024-12-02
2024-12-03
....
2024-11-18????? 주식데이터는 얼마???
list.index(값) ---> list[ ~~ 위치 ~~~] # 우회
df["날짜"] # 날짜로 바로 접근하고 싶다!!
--> 직접적으로 내가 세팅한 인덱스로 값을 "바로"접근하고 싶다!!
==> 물론 단점도 존재를 함 : 시간, 숫자, 텍스트,,,여러 자료형 다 처리!!!
: 속도에 상당히 느린 단점!!!
: 적당한 사이즈의 데이터를 핸들링 하기에 편해!!!
( 메가~~기가~~수십 기가(???)~~~) XXXXX
but) 큰 사이즈(수십~~수백~~테라단위!!!) ,
실시간 데이터를 대응!!!
===> sql+gpu+pyspark etc
정답은 없는데,,,,sql
# 예) 삼성전자의 주가 데이터를 처리하고 싶다!!!
==> 종가 1개만 생각을 하자!!!!
80000, 83000,79000, 82000
==> 1차원으로 종가 가격만 모아두자!!!(리스트, array, etc)
# 오늘 가격은 얼마일까?> --> -1
지난 주 목요일은 얼마??---> 몇 번째인가 고민을 해야하마;;;;
-- 휴일/ 공휴일 끼어있으면 찾기가 애매함;;;
===> 정수인덱스 말고, 내가 원하는 날짜로 종가를 접근해보자!!
(접근 경로를 정수인덱스 말고, 날짜로 추가하자!!!)
# 예) 주식 가격 데이터 있다고 가정
--> 값 :10000, 10300, 9900, 10500, 11000
# 생성1) 쌩 파이썬 리스트
stock_price_list = [ 10000, 10300, 9900, 10500, 11000]
# 생성2) numpy 의 array
stock_price_arr = np.array(stock_price_list )
# 생성3) pandas --> 1차원 --> Series : S대문자..
stock_price_Series = pd.Series( stock_price_list )
stock_price_list
[10000, 10300, 9900, 10500, 11000]
stock_price_arr
array([10000, 10300, 9900, 10500, 11000])
stock_price_Series
0
dtype: int64
0 10000 1 10300 2 9900 3 10500 4 11000
# 1번 주식 가격에 대한 접근
print( stock_price_list[0])
print( stock_price_arr[0])
print( stock_price_Series[0])
10000
10000
10000
# 1번 주식 가격에 대한 접근 : 슬라이싱
print( stock_price_list[0:4])
print( stock_price_arr[0:4])
print( stock_price_Series[0:4])
[10000, 10300, 9900, 10500]
[10000 10300 9900 10500]
0 10000
1 10300
2 9900
3 10500
dtype: int64
# --> 0번째하고 4번째 데이터만 보고 싶다1!!!
stock_price_list[ [0,4]]
TypeError
stock_price_arr[ [0,4]]
array([10000, 11000])
stock_price_Series[ [0,4]]

--> 나만의 인덱스를 만들어 보고자 함!!
stock_price_Series_index = pd.Series(
# 정보 : 진짜 리얼한 데이터들,
# : 데이터들을 접근할 수 있는 나만의 인덱스..
data = [ 10000, 10300, 9900, 10500, 11000],
index = ["2024-12-01","2024-12-02","2024-12-03",
"2024-12-04","2024-12-5"]
)
stock_price_Series_index
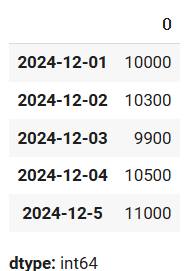
stock_price_Series_index[0]
<ipython-input-14-582ae4b44d1a>:1: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
stock_price_Series_index[0]
10000
stock_price_Series_index[0:4]

stock_price_Series_index["2024-12-03"]
9900
stock_price_Series_index["2024-12-01":"2024-12-03"]
# --> 정수 인덱스로 슬라이싱 : 끝 점이 빠지게 됨!!
# 내가 만든 인덱스로 슬라이싱 : 끝점이 포함이 됨!!!

stock_price_Series_index[ [0,4]]
<ipython-input-18-68bbe721acb>:1: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
stock_price_Series_index[ [0,4]]

stock_price_Series_index[ ["2024-12-01","2024-12-5"]]

stock_price_Series_index["2024-12-05"]
# --> 쌩 파이썬의 dict의 key처럼 Exact Matching!!!
# 대소문자/공백/패딩 etc : 오타에 유의하셔야 함!!!!!
KeyError: '2024-12-05'
# numpy에서 하는 것들이 거의 다 됨!!!
==> 불리언 인덱싱!!! ==> 조건 필터링!!!!
주식 가격이 10000보다 큰 데이터만 추려서 보자!!!!!
stock_price_Series_index[ stock_price_Series_index > 10000]

stock_price_Series_index > 10000

# 참고) dict와 상당히 유사!!!! 동작 유사!!! key - value
pandas index(정수,내가만든것) + value
stock_price_Series_index.index
Index(['2024-12-01', '2024-12-02', '2024-12-03', '2024-12-04', '2024-12-5'], dtype='object')
stock_price_Series_index.values
array([10000, 10300, 9900, 10500, 11000])
stock_price_Series_index +1000

stock_price_Series_index

# 참고) in : 자료형이 쌩파이썬의 dict ---> key 값 중심 체크!!!!
쌩파이썬의 list ---> value 중심으로 체크!!!!
pandas S/DF/P ===> index 중심으로 체크1!!!
"2024-12-10" in stock_price_Series_index
False
"2024-12-05"in stock_price_Series_index
False
"2024-12-5" in stock_price_Series_index
True
10300 in stock_price_Series_index
False
# 알아둘 부분 : 쌩파이썬의 dict < --- > pandas하고 연결성....
===> 데이터 수집을 하는 과정에서 상호호환으로 사용할 수도 있음!!!!
(크롤링할 때 사용해보겠습니다...)
s_data = {"APPL":1000, "MS":2000, "TSLA":3000}
s_data
{'APPL': 1000, 'MS': 2000, 'TSLA': 3000}
s_data["APPL"]
1000
s_data[0]
KeyError: 0
s_data_Series = pd.Series(s_data)
s_data_Series

s_data_Series["APPL"]
1000
s_data_Series[0]
<ipython-input-41-5ed2c8b0f14b>:1: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]` s_data_Series[0]
1000
#
s_data = {"APPL":1000, "MS":2000, "TSLA":3000}
ticker = ["GOOGLE","APPL","MS","META"]
s_2 = pd.Series(s_data,
index= ticker)
s_2

===> 결측치에 대한 발생을 늘 염두를 해야 함!!!
why? 파이썬은 or틱하게 돌아감...
엄밀하게 잘 하는 친구가 아니네요...
에러가 표면적으로 잘 발생하지 않음!!!!!
---> pandas : NaN
mysql : null ==> is null, is not null
s_1 = pd.Series(s_data)
s_1

s_2

s_1 + s_2
# ==> numpy의 기본적인 벡터연산의 특징!!!!
# 단, 위치 순서 중심으로 벡터연산을 하는 것이 아니라..
# index 중심으로 벡터 연산을 수행을 함!!
# +++ pandas에서는 index에서는 대충 or틱하게 처리를 함...
# 원하는 않은 row가 생성이 될수 있음!!!!
# 데이터의 수 꼭!!체크들을 해야 함!!!

# 참고) 결측치에 대한 처리
==> 자주 사용되는 메서드.
.isnull() : 너 값이 결측값이니? T/F
.notnull():너 값이 정상이지? T/F
temp = s_1 + s_2
temp

temp.isnull()

# 실제 받은 데이터 중에서,,,결측치만 체크하고 싶다..
==> 결측데이터만 추려서 보고 싶다!!!!!
temp[ temp.isnull() ]

# 정상적인 값들만 있는 데이터만 보자!!!!
temp[ temp.notnull()]

# 주의!!!
# 위의 isnull(), notnull() 메서드들이 FM적으로 맞는 말이고, 기능!!!!
# 실제 데이터들을 처리하다보면,,,,,,이 기능에서 누락되는 애들이 있음!!!
""
" "
None
# --> 코드적인 부분만이 아니라,,,실제 데이터들을 보면서 더블체크!!!!!
# 결측데이터 쪽 : NaN, "", None
# 기타
temp.ndim
1
temp.shape
(5,)
len(temp)
5
temp.dtype
dtype('float64')
### -------> 값에 대한 접근을 기존 리스트/array/pandas 유사점
: 경고!!! AM적인 방법으로 값들을 접근을 했어요!!
*** pandas에서 값에 대한 접근 방식 : FM적인 방법을 알아보려고 함!!****
# 기존의 방식 : 인덱스 자리에 내가 원하는 것을 요구하자!!!
=> 정수, 슬라이싱, 리스트 etc
+ 내가만든거, 내가만든걸로슬라이싱, 내가만든리스트들,,
+ 조건식 기반의 불리언 인덱싱!!!
===> 앞의 결론 : pandas[ 대충 던지면 하더라!!! ]
원하는 값들이 나오기는 함!!!!
but 많은 경우에 대해서 하건, 빈번하게 하면 속도이슈!!!!
FM적인 방법을 사용을 해야,,,적당한 속도를 보장을 받을 수 있음!!!
# pandas에서 FM적으로 명시적으로 값을 접근하는 방법을 만들어 둠!!!
값에 대한 접근을 바라보는 관점 : 1개 값 접근 vs 여러개 값 접근
1개 값에 대한 접근 1) at : 내가 만든인덱스 1개로 접근
2) iat : 태생적인 정수인덱스 1개 값 접근
여러개 값에 대한 접근 1) loc : 내가 만든인덱스로 여러개 값 접근
2) iloc : 태생적인 정수인덱스로 여러개 값 접근
# 참고) 이 부분들은 계속 버전에 따라서 변경되고 있음..
--> 단순 구글링을 하면,,오래전 자료가 나와서 안 맞을 수 있음!!
--> 최근 문서 기준으로 하세요1!!!
# 결론!!!) 내가 만든 인덱스로 접근 vs 태생적인 정수인덱스 접근!!!
+ 1개 값을 접근 vs 여러개 값을 접근!!
# 참고) 1개 값을 iloc, loc를 가지고도 할 수 있음!!!
데이터가 많아지면,,속도 차이가 남!!!
stock_price_Series_index = pd.Series(
# 정보 : 진짜 리얼한 데이터들,
# : 데이터들을 접할 수 있는 나만의 인덱스..
data = [ 10000, 10300, 9900, 10500, 11000],
index = ["2024-12-01","2024-12-02","2024-12-03",
"2024-12-04","2024-12-5"]
)
stock_price_Series_index

stock_price_Series_index[0]
<ipython-input-56-82ae4b44d1a>:1: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
stock_price_Series_index[0]
10000
# ex) 태생적인 정수인덱스로 접근 & 0번째 1개 값 --> FM
stock_price_Series_index.iat[0]
10000
stock_price_Series_index.iloc[0]
# -> 일반적으로 panda에서 자료가 많을 수록 [0] >>>>>>>> iloc[0]>iat[0]
# 명확하게 1개 값을 접근하겠다 : at/iat
10000
# ex) 2024년 12월 4일 주식 가격은 얼마입니까?
# ---> 내가 만든 인덱스 & 1개 요청 : at
stock_price_Series_index.at["2024-12-04"]
10500
stock_price_Series_index.iat["2024-12-04"]
ValueError: iAt based indexing can only have integer indexers
# ex) 0번째 부터 4번째 날의 데이터의 주식가격을 다 보여주세요!!!
stock_price_Series_index[:4]

stock_price_Series_index.iloc[:4]

# ex) 2024년 12월 2일 부터 2024년 4일까지 주가데이터 보여주세요!!!
stock_price_Series_index["2024-12-02":"2024-12-04"]

stock_price_Series_index.loc["2024-12-02":"2024-12-04"]

****** 정확하게 파악을 하세요!!!!
===> 본인 코드 작성할 때도 이것을 기준으로 코드 작성하세요!!!
명시적으로 작성하세요!!!!
# 참고) 수치연산을 numpy을 포함--> 간단한 연산들
stock_price_Series_index.sum()
51700
sum(stock_price_Series_index)
51700
stock_price_Series_index.count()
5
len(stock_price_Series_index)
5
stock_price_Series_index.max()
11000
max(stock_price_Series_index)
11000
# 정리!!!
쌩 파이썬의 리스트 ---> numpy array ---> pandas Series
차원x 차원o 오로직1차원
정수인덱스 정수인덱스 정수+내가만든것
at/iat/loc/iloc
벡터연산(위치중심) 벡터연산기본(index중심)
# 2D차원에서 다루는 DataFrame
---> nunmpy array : 2D
---> 기능의 동작 : pandas 1D Series ++ 2차원인 부분만
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 11일차 - 1 (24.12.18) (0) | 2024.12.18 |
|---|---|
| ASAC 빅데이터 분석가 과정 10일차 - 3 (24.12.17) (0) | 2024.12.17 |
| ASAC 빅데이터 분석가 과정 10일차 - 1 (24.12.17) (1) | 2024.12.17 |
| ASAC 빅데이터 분석가 과정 9일차 - 2 (24.12.16) (0) | 2024.12.16 |
| ASAC 빅데이터 분석가 과정 9일차 - 1 (24.12.16) (1) | 2024.12.16 |