03_pandas_2D_DataFrame
# 앞에서 한 1차원 Series 자료형을 확장!!!
=--> 2차원으로 확장!!!!!!
# pandas의 2차원 자료형 : DataFrame( Excel 1개 시트!! )
===> 코드적 : 2중 for문이 기본 형태!!!
+ 벡터연산을 기본 : 기능을 줄 단위로 코드가 간결하게 표현!!
+ 내가 만든 인덱스 : 가로index, 세로column
+태생적인 가로 정수 인데스
+태생적인 세로 정수 인덱스!!
import numpy as np
import pandas as pd
d = [1,2,3,4,5]
d_series = pd.Series(d)
d_series

d_df = pd.DataFrame(d)
d_df

# 용어 정리 : DataFrame에서 내가 만든 인덱스를 부여할 수 있음
==> 인덱스(가로, 세로) + 태생적인 정수 인덱스(가로,세로)
가로줄에 대한 인덱스 : index
세로줄에 대한 인덱스 : columns
d_df.index
RangeIndex(start=0, stop=5, step=1)
d_df.columns
RangeIndex(start=0, stop=1, step=1)
# 참고) 비공식적인 코드들이 상당히 많아요!!!!!
===> 가볍게 보고 땡하는 코드들이 많아서,,,배치처리에 사용하면 문제가 됨!!
주의해서 보셔야 함!!~
# 할 일 : 내가 원하는 컬럼의 이름 변경!!!
FM : rename
AM : 세로 인덱스(columns)접근해서 수정하는 방법.
d_df.columns = ["col1"]
d_df

d_df["col1"]
# --> 비공식적인 컬럼에 대한 값 접근 방법!!!
# 간단하게 2d DF에서 컬럼 값을 확인할 때 종종 사용!!!
# df[컬럼명]: 비공식적으로 대충 컬럼에대한 값을확인할 때....

type( d_df)

type(d_df["col1"])

# DataFrame에서 2차원 자료형!!!
--> 1개 컬럼을 선택 :
자료형의 차원이 1차원으로 변경 : Series 자료형을 변경!!!
2D DF --> 1개 컬럼 ---> 1D Series
==> 대량의 데이터를 일괄처리하는 batch코드에서는 주의해야 함!!!
# 할 일 : 새로운 컬럼을 추가
--> 전제 조건 : 기존에 DF이 있다고 가정을 하고,,,,
AF
df["컬럼명"] = [여러개 값]
d
[1, 2, 3, 4, 5]
d_df

d_df["newcol2"] = d
d_df

d_df["newcol3"] = 10
d_df

# 가정 : 기존 col1의 속성값 + newcol3의 속성값을 더해서
더 좋은 새로운 지표를 하나 만들고 싶다!!!!
컬럼을 추가하고 싶다!!!!
==> 기존의 값을 바탕으로 새로운 값을 생성하겠다....(컬럼화!!!)
d_df["new"] = d_df["col1"] + d_df["newcol3"]
d_df
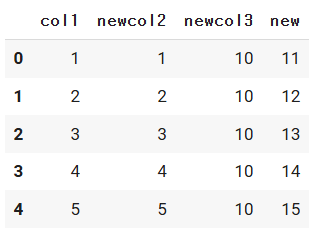
# 기존의 컬럼을 지울 때 : 지우는 방법도 많이 있어요!!
# 방법1) 파이썬의 del 지운다... : dict 지울 떄와 유사함!!!!
# del df["지울컬럼"]
del d_df["col1"]
d_df
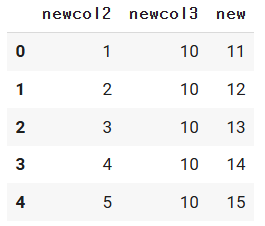
# 방법2) pandas에서 지우는 기능 : drop 메서드!!!
==> pandas는 기본적인 데이터 핸들링 위해서 만든 패키지!!!
여러 시도, 테스트들을 하면서 최종 결정을 끌고가야하는데,,
==> pandas 기본적으로 변경관련 메서드 바로 적용을 하지 X
바로 변경할 수 있도록 inplace = T/F(재할당없이 바로 변경해줘)
==> 가로줄 제거 : axis = 0
세로줄 제거 : axis = 1
d_df.drop("newcol3", axis=1 )

d_df
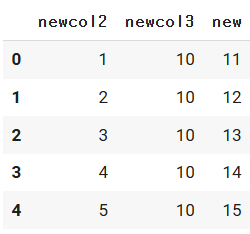
d_df.drop("newcol3", axis=1, inplace=True )
d_df

# ex) 가로줄 지울려고 함 : 샘플을 제거하려고 함!!!
# --> 가로줄 인덱스 2 데이터를 지워줘!!!!
d_df.drop(2, axis=0)

d_df

# 참고)
print(d_df.ndim)
print(d_df.shape)
print(d_df.shape[0])
print(len(d_df))
2
(5, 2)
5
5
# 참고!!! 중간에 데이터가 누락이 되면 주의해야 함!!!
d_df.drop(2, axis=0 , inplace=True)
d_df

# 아무 생각없이,,,가로줄 인덱스가 빵구가 난 것을 신경안쓰고,,,
# 가로줄 단위로 일을 처리한다!!!! 에러가 발생할 수 있음!!!
for i in range(len(d_df)):
print(i)
print(d_df.at[i,"new"])
0
11
1
12
2
KeyError: 2
d_df.index
Index([0, 1, 3, 4], dtype='int64')
for i in d_df.index:
#print(i)
print(d_df.at[i,"new"])
11
12
14
15
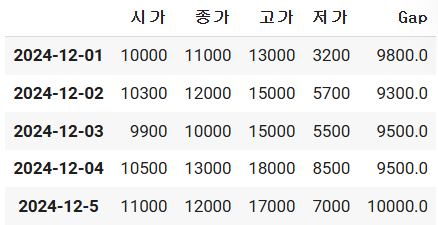
### 가상의 2D DataFrame 만들어서 동작 체크!! ###
stock_price_df = pd.DataFrame(
data = [ 10000, 10300, 9900, 10500, 11000],
index = ["2024-12-01","2024-12-02","2024-12-03",
"2024-12-04","2024-12-5"]
)
stock_price_df
# --> 처음 생성하는 과정에서는 data의 수와 index의 수가 꼭 일치!!

# 1) 세로줄에 나만의 인덱스 부여 : 컬러명을 변경!!
FM적은 방법 : rename 잘 알아두셔야 함!!!!
==> 무엇을 무엇으로 변경해줘 dict
주의사항!!!! 에러를 잘 안 더짐!!!!
진짜 변경이 원하는대로 되었는지 더블체크!!
stock_price_df.rename( columns ={"0":"시가"})

stock_price_df.rename( columns ={0:"시가"})

stock_price_df

stock_price_df.rename( columns ={0:"시가"},
inplace=True)
stock_price_df

stock_price_df.rename( index={"2024-12-5":"2024-12-05"})

stock_price_df

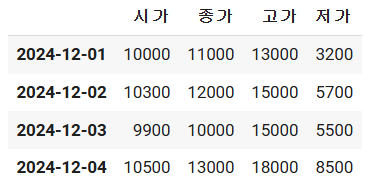
stock_price_df["종가"] = [11000,12000, 10000,13000, 12000]
stock_price_df["고가"] = [13000,15000,15000,18000,17000]
stock_price_df["저가"] = [3200,5700,5500,8500,7000]
stock_price_df

# 2D 값에 대한 FM 접근을 하겠습니다..
==> 1개 값을 접근(at,iat) vs 여러개 값은 접근(loc,iloc)
+ 2차원이기 때문에 값에 대한 인덱스 가로/세로 : 2개
stock_price_df.iat[0,0]
10000
stock_price_df.iat[0,1]
11000
stock_price_df.at["2024-12-02","종가"]
12000
# ex) 2024년 12월 3일 시가하고, 고가는 얼마야?
stock_price_df.loc["2024-12-03", ["시가","고가"]]

type(stock_price_df.loc["2024-12-03", ["시가","고가"]])

stock_price_df.iloc[2, [0,2]]

# 참고) 원하는 컬럼/index 어디에 위치하는지 찾아주는 메서드
==> get_loc()
stock_price_df.columns.get_loc("시가")
0
stock_price_df.columns.get_loc("고가")
2
stock_price_df.index.get_loc("2024-12-03")
2
stock_price_df.iloc[stock_price_df.index.get_loc("2024-12-03"),
[stock_price_df.columns.get_loc("시가"),
stock_price_df.columns.get_loc("고가")]]

target_cols = ["시가","고가"]
target_cols_idx = [stock_price_df.columns.get_loc(c) for c in target_cols ]
target_cols_idx
[0, 2]
target_dates = ["2024-12-03"]
target_dates_idx = [stock_price_df.index.get_loc(c) for c in target_dates ]
target_dates_idx
[2]
stock_price_df.iloc[target_dates_idx,target_cols_idx ]

# 2024-12월 -1일 부터 4일까지, 시가/종가/고가/저가 데이터를 보여줘!!!
stock_price_df.loc["2024-12-01":"2024-12-04", "시가":"저가"]

stock_price_df.loc["2024-12-01":"2024-12-04", :]

stock_price_df.loc["2024-12-01":"2024-12-04", ::-1]

stock_price_df.iloc[0:4, :]
# 2024년 12월 3일 , 시가 데이터만 보여주세요1!!
stock_price_df.at["2024-12-03","시가"]
9900
stock_price_df.loc["2024-12-03","시가"]
# --> 가능한 코드이지미나, 속도적인 이슈갈 있을 수 있는 코드!!1
# ===> 최대한 명확하게 1개 값이면, at/iat으로 사용하세요!!
9900
# 모든 날짜들에 대해서, 시가/저가 컬러만 보여주세요!!!!!
stock_price_df.loc[:, ["시가","저가"]]

stock_price_df[ ["시가","저가"]]
# --> 되기는 하는 코드코인데,,,
# FM적인 코드가 아니고, 조회에 조회를 코드다 보니..
# 속도 이슈가 있을 수 있는 코드임!!!!!
# ==> iloc/loc 변경해서 FM적으로 사용하세요!!!!!!!!

# 정리)
값에 대한 접근을 할 떄 FM적인 방법을 사용하세요!!!!
==> at/iat/loc/iloc
++ 2D DataFrame에서는 가로/세로 대해서 내가 만든것 or
태생적 정수인덱스!! 통일!!
==> 가로/세로를 다 하나의 기준으로 몰아야 함!!!!
get_loc()
stock_price_df.T

# 참고) pandas는 기본적으로 가로줄에 index 인덱스라고 이야기르 ㄹ함.
===> 유사한 기능들이 존재를 함!!
--> 가로줄에 대한 인덱스를 수정 : rename( index=~~~)
--> 가로줄에 대한 인덱스를 초기화(정수): reset_index()
--> 가로줄에 대한 인덱스를 내가 원하는 것만 세팅 : reindex()
+++ 원본을 변경하는 친구들이여서 inplace=T/F
stock_price_df.rename(index={"2024-12-5":"2024-12-05"})

stock_price_df.reset_index()

stock_price_df.reindex(["2024-12-01","2024-12-03"])

stock_price_df.reindex(["2024-12-03","2024-12-02","2024-12-01"])

# 정렬!!!) 이미 만들어져 있음!!!!
--> pandas 에서도 이미 만들어 두었습니다..
==> 정렬에 대한 기준을 가로줄/ 세로줄 선택!!!!
1. 가로줄index 이름 중심으로 정렬/ 세로줄 columns 이름 중심 정렬
sort_index( axis=0, 1)
2. 값 자체로 정렬 : sort_values()
stock_price_df

# ex) 컬럼명을 중심으로 DF을 정렬해보자!!!!
===> sort_index
===> 세로줄 : axis = 1
===> 오름/내림 : ascending=T/F( 기본값: 오름차순)
stock_price_df.sort_index(axis=1, ascending=True)

stock_price_df.sort_index(axis=1, ascending=False)

# ex) 최근 데이터 기준으로 데이터르 뒤짚어서 볼까!!!!
===> 오래전 날짜 인덱스 : 뒤로
최근 날짜 인덱스 : 앞으로
stock_price_df.sort_index(axis=0, ascending=False)

# ex) df의 내부의 값을 중심으로 정렬!!!!
===> 내부의 어느 줄을 기준으로 그 안의 값을 기준해서 정렬!!!
stock_price_df.sort_values(by="고가")

stock_price_df.sort_values(by="고가", ascending=False)

# ex) 값을 가지고 정렬하는 입장에서 2번째 정렬기준
===> 정렬 기준을 순서대로 나열하면 됨!!!
stock_price_df.sort_values(by=["고가","시가"], ascending=False)

stock_price_df["종가"]

# 참고) rank 등수 선정 ==> 자세한 기준은 메뉴얼!!!
stock_price_df["종가"].rank()

stock_price_df["종가"].rank(method="max")

stock_price_df["종가"].rank(method="max", ascending=False)
# ---> sql : rank()/dense_rank()/ row_numbers() --> over( order by ~~ASC/DESC)

******* 줄단위에 연산을 통해서 데이터 전처리 *******
# 목적 : 줄 단위로 값들을 변경하거나 처리하고자 하는 일을 쉽게!!!
==> 하려는 일에 대해서 줄단위로 무엇을 할지 규칙적으로 할 때
# sort/sorted(x, key=lambda x:~~~~)
==> apply + lambda : 줄 단위로 무엇을 할지 기술!!!!!
(개별 데이터는 신경쓰지 않고, 줄 단위로 기능 /규칙 중심 코드!!)
==> 코드의 가독성이 중심!!!!!!!!!! 효율성/빠름 XXXX
(전통 통계 프로그램 : SAS, R, SPSS etc )
stock_price_df

# ex) 날짜별로 최고가의 가격만 보고 싶다!!!!
==> 체크 : 일단 하려는 일이 줄 단위로 동일한지 OK
기능 : 임의의 가로줄에서 여러개 값 중에서 최고값 선택!!!
apply(줄을 돌려주는 역할) + lambda (할일에 대한 기술)
stock_price_df.apply( lambda x: x.max(), axis= 1) # ?????

stock_price_df.apply( lambda x: x.max(), axis= 0)

# ex) 날짜별로 최고값과 최저값의 차이들을 계산해주세요..
체크 : 일단 하는 일이 줄 단위로 동일하냐 OK
기능 : 그 줄에서 최고값 - 그 줄에서 최저값
stock_price_df.apply(lambda x:x.max()-x.min() )

stock_price_df.apply(lambda x:x.max()-x.min(),axis=1)

# ex) 기존의 있는 값을 바탕으로(index) 추가
stock_price_df["Gap"] = stock_price_df.apply(lambda x:x.max()-x.min() , axis=1)
stock_price_df
+++ 직접 값들을 롤링해서 하는 것~~~~~
***리스트/어레이/Series/DF
==> 전반적인 내용/흐름
Pandas에서 FM적으로값을 접근하는 방식
//양/늑대 ;; --> 아침..
퇴실 버튼 체크
내일 봐용 --> 교재 2권 챙기기
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 11일차 - 2 (24.12.18) (2) | 2024.12.18 |
|---|---|
| ASAC 빅데이터 분석가 과정 11일차 - 1 (24.12.18) (0) | 2024.12.18 |
| ASAC 빅데이터 분석가 과정 10일차 - 2 (24.12.17) (0) | 2024.12.17 |
| ASAC 빅데이터 분석가 과정 10일차 - 1 (24.12.17) (1) | 2024.12.17 |
| ASAC 빅데이터 분석가 과정 9일차 - 2 (24.12.16) (0) | 2024.12.16 |