05_json_kobis_api
# JSON으로 되어 있는 정보를 파이썬으로 접근하기 위해서는 순차적으로 한 depth 접근해야 한다!
==> 하나씩 보면서 순차적으로 접근하자! 정수/key
그냥 눈에 보이는대로, 하나씩 처리하면 된다!
# 내가 원하는 데이터가 웹 상에 존재할 때!
1. API 형태로 제공하는 경우
===> json 제공 : json패키지 --> 파이썬 list/dict 형 변환하자!
--> 정수인덱스,key 중심으로 순차 접근하자!
===> xml 제공 : bs4 --> BeautifulSoup : Tag(숏컷)
# 2. 그냥 웹 사이트에 있을 경우 (사람인vs인쿠르트, 구글 등)
2-1) 정적인 사이트으므로 주소를 원한는대로 변경하자!
++ 내가 원하는 정보에 대한 주소 룰 찾아야 함!!!
2-2) 원하는 정보의 사이트 주소가 없거나, 숨겨져 있는 경우
==> 숨겨진 주소를 찾는 시도를 해보자
==> 동적으로 움직이는 사이트들은 "셀레니움"을 활용하자!
(코드를 통해서 웹브라우저를 컨트롤 하려고 할 수 있다 : 정보)
//속도가 많이 느리다
// 해당 사이트를 너무 빠르게 접속하면 벤 당한다
//사람이 접속하는 것 처럼 위장해야 한다
# 3. 파일로 존재하는 경우 : read_ (공공데이터의 경우)
# 실습 API : 영화진흥위원회
개인적으로 받은 key 를 사용해야 한다.
key : e5b253a83f004635cd7fd625e9a0a839
나의 key : 0bdd88b78082bffc83fa2b9fff692199
# 실습 목적 : 영화진흥위원회에 있는 정보들 중에서
API를 통해서
최신 영화 관련 코드, 최신 영화 제목, 영문제목, 장르, 개봉일 수집 가능!
(++ 상세 정보: 배우,스탭명,세부장르,,,,)
// ?를 기준으로 베이스 url과 요청 인터페이스로 구분된다.
# 1. 내가 원하는 정보가 어디에 있는지 직접 체크!
==> api 메뉴얼을 봐야 한다!
: 영화목록페이지 api요청!
# 2. 내가 좀 더 구체적으로 요청할 수 있는 사항들이 체크!
(요청인터페이스 항목들 체크!)
==> 지금 시점의 최신 영화 목록을 요청 할 수는 있는거 있다!
10개는 좀 적다면
==> 50개 정도 요청하고 싶으면
메뉴얼 요청인터페이스 : itermPerPage에 요청하자!
==> 요청사항을 늘리고 싶을 때!
&요청파라미터=값 ...
# 3. 통신 관련 모듈 http : urlib, requests etc
# 4. 요청할 양식을 주소에 기록 --> 전송 : JSON
# 5. 요청해서 받은 정보 : json양식정보 --> json패키지 접근 쉽게!
# 6. pandas의 DataFrame에 잘 담아보자!
# 필요한 패키지들
import pandas as pd
import urllib.request # <--- 파이썬에서 http통신을 위한
import json # <--- 요청한 json양식 처리 편의성
# Step1) 내가 필요한 정보들을 요청하는 주소 생성!
==> 메뉴얼을 잘 보면서 하자
get : baseurl?요청할파라미터=요청할값&~~~
# 참고) 일반 사이트들은 이 요청파라미터들을 후킹(가로챈다)! --> 뒤져서 찾아야 한다
Dart 할 때 보겠습니다.Daum 금융 사이트 등..
# 기본 주소
url_p1 = "http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json"
# 필수 항목 : key
key = "e5b253a83f004635cd7fd625e9a0a839"
# 부가적으로 요청사항 : itemPerPage --> 50개로 확장..
url_p2 =50
# ==> 위의 사항이 반영된 주소
url = url_p1 +"?key=" + key+"&itemPerPage="+url_p2
url
'http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json?key=e5b253a83f004635cd7fd625e9a0a839&itemPerPage=50'
# 참고) 내가 50개를 요청을 한다고 해도 꼭 50개가 온다는 보장은 없다!
===> 실제 받은 데이터의 수를 꼭 체크하자!
# step2) urlllibn --> http
movie_page = urllib.request.urlopen( url)
movie_data = json.loads( movie_page.read().decode("utf-8") ) # json.loads()없으면 에러생김
movie_data
#코드 생략
type(movie_data)
dict
movie_data.keys()
dict_keys(['movieListResult'])
type(movie_data["movieListResult"])
dict
movie_data["movieListResult"].keys()
dict_keys(['totCnt', 'source', 'movieList'])
type(movie_data["movieListResult"]["movieList"])
list
movie_data["movieListResult"]["movieList"][0]
{'movieCd': '20244316',
'movieNm': '더 엑소시즘',
'movieNmEn': 'The Exorcism',
'prdtYear': '2024',
'openDt': '20250115',
'typeNm': '장편',
'prdtStatNm': '개봉예정',
'nationAlt': '미국',
'genreAlt': '공포(호러)',
'repNationNm': '미국',
'repGenreNm': '공포(호러)',
'directors': [],
'companys': []}
# 본인이 요청한 영화정보에 대한 결과를 가지고..
# Q-1) 1번 영화의 정보를 덩어리로 출력해보세요!!!
movie_data["movieListResult"]["movieList"][0]["movieNm"]
{'movieCd': '20244316',
'movieNm': '더 엑소시즘',
'movieNmEn': 'The Exorcism',
'prdtYear': '2024',
'openDt': '20250115',
'typeNm': '장편',
'prdtStatNm': '개봉예정',
'nationAlt': '미국',
'genreAlt': '공포(호러)',
'repNationNm': '미국',
'repGenreNm': '공포(호러)',
'directors': [],
'companys': []}
# Q-2) 1번 영화의 영화코드값만 출력해보세요!!!
movie_data["movieListResult"]["movieList"][0]["movieCd"]
'20244316'
# Q-3) 1번 영화의 영화제목(국문) 출력
movie_data["movieListResult"]["movieList"][0]["movieNm"]
'더 엑소시즘'
# Q-4) 1번 영화의 영화제목(영문) 출력
movie_data["movieListResult"]["movieList"][0]["movieNmEn"]
'The Exorcism'
# Q-5) 1번 영화의 개봉일 출력
movie_data["movieListResult"]["movieList"][0]["openDt"]
'20250115'
# Q-6) 1번 영화의 감독의 정보가 있다면,,,,
여러 명의 감독이 있다면, 처음 나타난 감독이름만 출력.
movie_data["movieListResult"]["movieList"][20]
{'movieCd': '20247017',
'movieNm': '대가족',
'movieNmEn': 'About Family',
'prdtYear': '2023',
'openDt': '20241211',
'typeNm': '장편',
'prdtStatNm': '개봉',
'nationAlt': '한국',
'genreAlt': '드라마,코미디',
'repNationNm': '한국',
'repGenreNm': '드라마',
'directors': [{'peopleNm': '양우석'}],
'companys': [{'companyCd': '20242702', 'companyNm': '게니우스 유한회사'}]}
movie_data["movieListResult"]["movieList"][0]["directors"][0]["peopleNm"]
IndexError: list index out of range
movie_data["movieListResult"]["movieList"][20]["directors"][0]["peopleNm"]
[{'peopleNm': '양우석'}]
# Q-7) 하다가 에러가 발생하면 어찌할지 고민을 해보세요!!!!!!
if movie_data["movieListResult"]["movieList"][0]["directors"]!=[]:
print(movie_data["movieListResult"]["movieList"][0]["directors"][0]["peopleNm"])
else:
print("감독정보없음")
감독정보없음
# Q-8) 1번 영화에 대한 코드/제목/제목영/개봉일/감독 정보 출력
print(movie_data["movieListResult"]["movieList"][0]["movieCd"])
print(movie_data["movieListResult"]["movieList"][0]["movieNm"])
print(movie_data["movieListResult"]["movieList"][0]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][0]["openDt"])
if movie_data["movieListResult"]["movieList"][0]["directors"]!=[]:
print(movie_data["movieListResult"]["movieList"][0]["directors"][0]["peopleNm"])
else:
print("감독정보없음")
print("*"*50)
20244316
더 엑소시즘
The Exorcism
20250115
감독정보없음
# Q-9) 2번 영화에 대한 코드/제목/제목영/개봉일/감독 정보 출력
print(movie_data["movieListResult"]["movieList"][1]["movieCd"])
print(movie_data["movieListResult"]["movieList"][1]["movieNm"])
print(movie_data["movieListResult"]["movieList"][1]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][1]["openDt"])
if movie_data["movieListResult"]["movieList"][1]["directors"]!=[]:
print(movie_data["movieListResult"]["movieList"][1]["directors"][0]["peopleNm"])
else:
print("감독정보없음")
20240110
엄청난 폭유녀 성욕 터진 날 무삭제판
Why The Wife Becomes A SEX Worker
감독정보없음
# Q-10) 3번 영화에 대한 코드/제목/제목영/개봉일/감독 정보 출력
.....50개 정도를 하는데,,,==> 코드화!!!!!
print(movie_data["movieListResult"]["movieList"][2]["movieCd"])
print(movie_data["movieListResult"]["movieList"][2]["movieNm"])
print(movie_data["movieListResult"]["movieList"][2]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][2]["openDt"])
if movie_data["movieListResult"]["movieList"][2]["directors"]!=[]:
print(movie_data["movieListResult"]["movieList"][2]["directors"][0]["peopleNm"])
else:
print("감독정보없음")
print("*"*50)
# .....50개 정도를 하는데,,,==> 코드화!!!!!
2024A054
마이 러브돌 2
My Next Doll
감독정보없음
# Q-11) 본인이 받은 모든 영화들에 대한 위의 정보를 출력해보세요!!!
===> for : 필요한 값 : 0~개별영화접근 인덱스 --> 영화가 몇개!!
tot_cnt = len(movie_data["movieListResult"]["movieList"])
for i in range( tot_cnt):
print(movie_data["movieListResult"]["movieList"][i]["movieCd"])
print(movie_data["movieListResult"]["movieList"][i]["movieNm"])
print(movie_data["movieListResult"]["movieList"][i]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][i]["openDt"])
if movie_data["movieListResult"]["movieList"][i]["directors"]!=[]:
print(movie_data["movieListResult"]["movieList"][i]["directors"][0]["peopleNm"])
else:
print("감독정보없음")
print("*"*50)
# 출력 생략
==> 위의 코드는 특별하게 문제가 있는것은 아님!!!
데이터가 아주 큰 상황에서 조회를 하는 경우는 비효율성!!!
==> ***데이터를 수집/처리:1개 데이터 단위!!!!!***
tot_cnt = len(movie_data["movieListResult"]["movieList"])
print("처리할 영화의 수:",tot_cnt)
for i in range( tot_cnt):
# ===> i번째 개별 영화에 대해서 처리 : 종합 정보
temp = movie_data["movieListResult"]["movieList"][i]
# ===> 개별 샘플에 대한 정보를 일단 가져오고, 여기서 필요한 정보 추출!!
print(temp["movieCd"])
print(temp["movieNm"])
print(temp["movieNmEn"])
print(temp["openDt"])
if temp["directors"]!=[]:
print(temp["directors"][0]["peopleNm"])
else:
print("감독정보없음")
print("*"*50)
# 출력 생략
==> 위의 과정은 개별 영화에 대한 정보를 출력하고 땡!!
: 개별 정보에 대한 접근하는 규칙이 제대로 되는지 체크1!!!
==> 이 정보들 어딘가 잘 담아두려고 함!!!!!
DataFrame 담으면 좋은데,,,,DataFrame 을 가지고 수집을 하면
상당히 무거운 친구!!!!!!!
: 가볍게 필요한 정보들만 추려서 핸들링 하고 싶음!! : 리스트/deque/dict etc
--> 나중에 한 번에 DF으로 틀을 생성하고 싶다!!!
tot_data = [
["20248961","사일런트 러브","Silent Love","","우치다 에이지"],
["2024A391","포에버 홈","Forever Home","20250115",""],
....
]for idx, data in enumerate(movie_data["movieListResult"]["movieList"]): print(idx) print(data) print("*"*50)
# ===> DF으로 형을 변환할 수 있음!!
# (list/deque + dict)
for idx, data in enumerate(movie_data["movieListResult"]["movieList"]):
print(idx)
print(data)
print("*"*50)
# 출력 생략
# 할 일 : 위의 정보들을 DF에 담아보자!!!
====> 방법1) list 계열을 활용해서 처리하자!!!(list/deque)
2차원으로 정확하게 변형을 하기 위해서
오/열 딱 맞아야 함!!!!!
전체 정보가 리스트에 유사2차원으로 담겨야 함!!
tot_data = []
for idx, data in enumerate(movie_data["movieListResult"]["movieList"]):
# data 변수 : 개별 영화의 정보 dict
# idx : 받은 영화의 정수 인덱스,,
i_code = data["movieCd"]
i_name = data["movieNm"]
i_name_e = data["movieNmEn"]
i_day = data["openDt"]
if data["directors"] != []:
i_dir = data["directors"][0]["peopleNm"]
else:
i_dir =""
#### ---> i번째 영화에 대한 정보는 다 추출을 하였음!!!
# 모아서,,,[] --> tot_data에 추가하면 됨!!!!
tot_data.append( [i_code,i_name, i_name_e,i_day,i_dir])
print("Done!!!!")
Done!!!!
tot_data
# 출력 생략
# 위에 각을 2차원으로 오/열 맞춘 리스트를 DF으로 변환!!!!
# ==> 틀을 씌어주려고 함!!! //pd.DataFrame()함수 중요!! --> data 와 colums 설정!
movie_df = pd.DataFrame(
data = tot_data,
columns = ["movieCd","movieTitle","movieETitle","openDay","DirName"]
)
movie_df
# 출력 생략
# 정리) 최대한 가볍게 데이터들을 수집을하고, 처리!!!
나중에 한 번 무거운 DF을 변환!!!!
+++ 중간에 너무 무거워지면 중간 중간 DF으로 짤라야 함!!!
list/deque 원소가 많아지면 ,,,이 친구들도 무거워 짐;;;;
속도 저하가 발생 함!!!
+++ 모니터링을 직접 하면서 중간 중간 처리를 해야 함!!!
***** 데이터 처리의 기준 : 1개 샘플을 기준으로 ~~~~~! *****
movie_df.head()

movie_df.head(3)

movie_df.tail()

# 할 일!!
1. 개봉일에 대한 정보를 바탕으로 년도 컬럼 추가!!
월 컬럼 추가!!
일 컬럼 추가!!
2. movieCd컬럼의 값을 보니,,,메뉴얼상 코드값!!!!
===> 코드값이 진짜로 유니크한지 체크!!!!!
: 유니크하다면,,,,DF의 가로줄index로 사용하고자 함!!!
"20250115"
'20250115'
"20250115"[:4]
'2025'
"20250115"[4:6]
'01'
"20250115"[6:]
'15'
==> apply+ lambda !!!!
주의!!!)전체 DF, 일부 DF만 필요한 것인지 정확하게 체크!!!
movie_df.loc[:,"openDay"].apply( lambda x : x[:4])
# 출력 생략
movie_df["year"] = movie_df.loc[:,"openDay"].apply( lambda x : x[:4])
movie_df["month"] = movie_df.loc[:,"openDay"].apply( lambda x : x[4:6])
movie_df["day"] = movie_df.loc[:,"openDay"].apply( lambda x : x[6:])
movie_df.head()
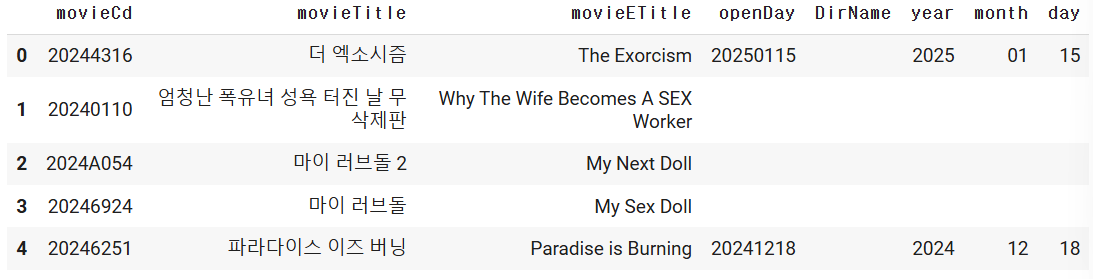
==> movieCd가 고유성!!!!
if 코드값이 유니크하다면 가로줄 인덱스로 사용하자!!!
len(movie_df.loc[:,"movieCd"].unique()) == len(movie_df)
True
--> 기존 DF에서 있는 기존의 컬럼을 가로줄 index로 역할 변경!!!
===> set_index
movie_df.set_index("movieCd")
# 출력 생략
movie_df.set_index("movieCd", inplace=True)
movie_df.head()
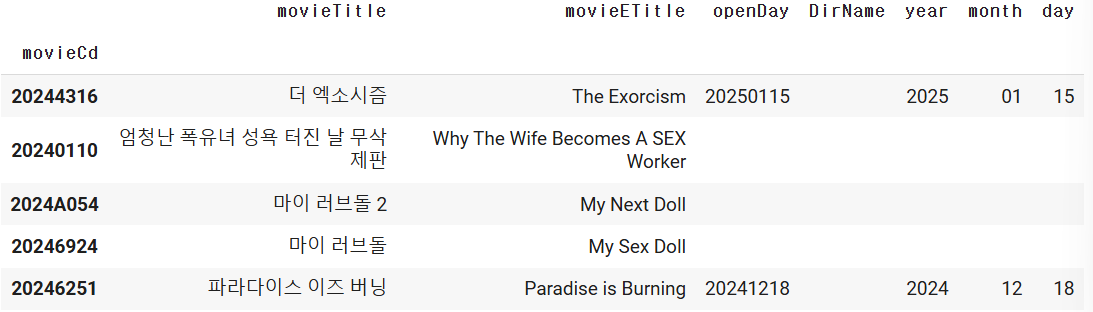
# DF에서 FM적으로 1번 영화에 대한 정보를 접근해보세요!!
movie_df.iloc[0, :]

movie_df.loc["20244316", :]

==> 의미 ; 개별 영황에 대한 접근 방식을
정수인덱스 이외에
kobis api가 부여한 영화 코드값으로도 접근이 가능함!!!
#참고)
수업시간에는 필요한 것들만 추려서 수집을 하였습니다!!
개인/조별/회사 프로젝트를 진행을 하겠다!!
==> 수집 가능한 정보들을 일단 다 수집을 하는 것이 좋습니다!!
: 나중에 필요없으면,,, 버리면 되지!!
==> 중간 수집한 정보들의 원본 로컬로 저장해두는 것도 방법!!
: 인터넷이 안될 수 있고, 다시 요청할 필요도 없음...
*** 할 때 최대한 다 하자!! & 중간 중간에 잘 저장!!
& 원본은 최대한 로컬에 저장을 해두자!!
# 내가 수집한 정보/ 처리한 정보들을 다른 사람과 공유해야 할 수도 & 중간 백업을 해야할 수도 있다.
==> 파일로 저장 or DB에 저장 etc...
csv(값, 구분자) ---> json, xml
excwl(값, 양식/꾸밈) ---> html etc
movie_df.head()
# 출력 생략
# DF을 백업하기!!
# 참고) 저는 지금 colab에서 하고 있어서 경로가 조금 다름!!
/content/kobis_api.csv
movie_df.to_csv(" /content/kobis_api.csv")
# 해외 회사의 경우
- 영문이름..
==> csv sep = ", "
DB에서 데이터에 문제가 생김 // 구분자를 잘 구별해서 쓰자
movie_df.to_csv(" /content/kobis_api.csv", sep = "@")
==> 한글이 인식을 제대로 안됨 구분도 제대로 안되어 보기 불편함
# 윈도우에서 한글을 사용할때
- ms쪽은 cp949 방식을 사용한다.
- 리눅스 : utf-8
movie_df.to_csv(" /content/kobis_api.csv", sep = "@", encoding="cp949")
==> 한글이 깨지는 경우는 해결!! 하지만 구분자가 @라서 가시적으로 불편함은 남아있다.
movie_df.to_csv(" /content/kobis_api.csv", sep = "@", encoding="utf-8")
# excel에 저장할 때!!
movie_df.to_excel("/content/kobis_api.xlsx")
==> 셀별로 구분해서 잘 저장됨!!
# 참고 : csv 파일로 수집된 정보를 pandas의 DF으로 불러오고자 한다면
temp_df = pd.read_csv(" /content/kobis_api.csv",sep="@")
temp_df
# 출력 생략
==> ","를 사용한 경우 에러가 생긴다.
movie_df.head()
# 출력 생략
# 할 일 : 앞에서 수집한 50개 영화에 대한 정보가 부족하다 느낀다.
보다 상세한 영화 관련 정보들을 추가 하고 싶다!!
속성에 대한 확장을 추가하자 ( 옆으로 확장 = 컬럼 확장!)
1. 장르에 대한 정보를 추가!! ( 1번 장르만 하겠다,없으면 빈칸으로!)
2. 출연한 배우의 수 추가!! ( 없으면 0으로 기록!)
3. 출연한 배우 중에서 1번 배우에 대해서 배역 이름, 배우의 이름을 추가!! (없으면 빈 문자열로 기록!)
// 내가 한 거
//강사님이 하신 거
#사전 체크 : 샘플 광해 영화에 대해서 체크!
# test : 광해 20124079 movieCd
base_url = http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json
# key, 영화코드
key = "e5b253a83f004635cd7fd625e9a0a839"
movie_code = "20124079"
url = base_url + "?key=" + key + "&movieCd=" + movie_code
url
http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json?key=e5b253a83f004635cd7fd625e9a0a839&movieCd=20124079
--> 위의 주소를 직접 통신으로 요청하고 받으면 된다
==> json으로 요청했으니 처리 편의성을 json 패키지를 사용해서 형을 변환하면 편리하다
res = urllib.request.urlopen(url)
temp_data = json.loads(res.read().decode("utf-8"))
temp_data
# 출력 생략
type(temp_data)
dict
temp_data.keys()
dict_keys(['movieInfoResult'])
type(temp_data["movieInfoResult"])
dict
temp_data["movieInfoResult"].keys()
dict_keys(['movieInfo', 'source'])
type(temp_data["movieInfoResult"]["movieInfo"])
dict
temp_data["movieInfoResult"]["movieInfo"].keys()
dict_keys(['movieCd', 'movieNm', 'movieNmEn', 'movieNmOg', 'showTm', 'prdtYear', 'openDt', 'prdtStatNm', 'typeNm', 'nations', 'genres', 'directors', 'actors', 'showTypes', 'companys', 'audits', 'staffs'])
# 광해 영화에 대해서 상세 정보들을 출력해보세요!!!
q1) 장르에 대한 정보를 출력하세요! --> generes
q2) 출연한 배우의 수 출력하세요!
q3) 1번 배우의 이름을 출력!
q4) 1번 배우가 맡은 배역의 이름을 출력!
temp_data["movieInfoResult"]["movieInfo"]["genres"][0]["genreNm"]
'사극'
len(temp_data["movieInfoResult"]["movieInfo"]["actors"])
36
temp_data["movieInfoResult"]["movieInfo"]["actors"][0]
{'peopleNm': '이병헌',
'peopleNmEn': 'LEE Byung-hun',
'cast': '광해/하선',
'castEn': ''}
temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["peopleNm"]
'이병헌'
temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["cast"]
'광해/하선'
# 추가적인 상세 정보를 추가하고 싶다!!!
==> 1번 장르 이름,
==> 배우의 수
==> 1번 배우의 이름, 배역
movie_df["Genere"]= ""
movie_df["ActNum"]= ""
movie_df["ActName"]= ""
movie_df["ActCast"]= ""
movie_df.head()
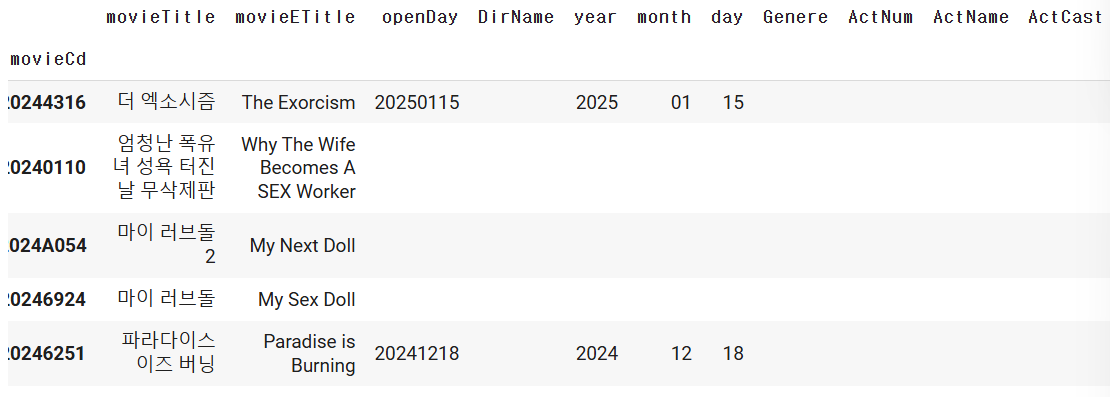
# step1) 지금 개인별로 수집한 영화 DF에서
-> 이 영화들에 대한 상세 정보를 요청하는 url 출력!
-> for문을 통해서 i번째 영화에 대한 상세 정보 요청 url
for i in range(len(movie_df)):
print(i)
# 출력 생략
base_url ="http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json"
key = "e5b253a83f004635cd7fd625e9a0a839"
for i in movie_df.index:
url = base_url + "?key="+key+"&movieCd="+str(i)
print(url)
#출력 생략
# step2) i번째 영화에 대한 상세정보를 요청하는 url 완성!
=> 코비스 서버 api에 직접 주소를 요청!
++ 참고) 상태에 대한 체크 코드!도 있지만 skip
=> 받은 결과에 대해서 json 패키지로 처리!
++ 중간에 에러가 발생하면 원인을 찾아서 코드화하자!
base_url ="http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json"
key = "e5b253a83f004635cd7fd625e9a0a839"
for i in movie_df.index:
url = base_url + "?key="+key+"&movieCd="+str(i)
temp_res = urllib.request.urlopen(url)
temp_data = json.loads( temp_res.read().decode("utf-8"))
# ---> 혹시 개별 상세 영화 정보가 안 땡겨지면,,,에러 부분을 체크!!!
# : 룰을 체크!!!!!!!
print(temp_data)
print("*"*80)
# 출력 생략
# step3) i번째 영화에 대한 상세정보 중에서 필요한 정보를 추출
=> i번째 가로줄에 맞는 칸에 정보를 기록/추가!
*** 개인별로 아래 영화 상세 정보를 요청해서 DF로 만드는 것을 해보자!
base_url ="http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json"
key = "e5b253a83f004635cd7fd625e9a0a839"
for i in movie_df.index:
url = base_url + "?key="+key+"&movieCd="+str(i)
temp_res = urllib.request.urlopen(url)
temp_data = json.loads( temp_res.read().decode("utf-8"))
# ---> 혹시 개별 상세 영화 정보가 안 땡겨지면,,,에러 부분을 체크!!!
# : 룰을 체크!!!!!!!
# ---> 장르, 배우 수, 배우이름, 배역이름 출력!!!!
if temp_data["movieInfoResult"]["movieInfo"]["genres"]!= []:
print(temp_data["movieInfoResult"]["movieInfo"]["genres"][0]["genreNm"] )
else:
print("장르X")
# 배우수
if temp_data["movieInfoResult"]["movieInfo"]["actors"] != []:
print( len(temp_data["movieInfoResult"]["movieInfo"]["actors"]))
print(temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["peopleNm"] )
print(temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["cast"] )
else:
print("배우 정보 X")
print("1번 배우 없음!")
print("1번 배역 없음")
print("*"*80)
# Step 4) ==> DF에 i번째 가로줄에 맞는 칸에 정보를 기록/추가!!!(V)
movie_df.head()
# 출력 생략
base_url ="http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json"
key = "e5b253a83f004635cd7fd625e9a0a839"
for i in movie_df.index:
url = base_url + "?key="+key+"&movieCd="+str(i)
temp_res = urllib.request.urlopen(url)
temp_data = json.loads( temp_res.read().decode("utf-8"))
# ---> 혹시 개별 상세 영화 정보가 안 땡겨지면,,,에러 부분을 체크!!!
# : 룰을 체크!!!!!!!
# ---> 장르, 배우 수, 배우이름, 배역이름 출력!!!!
if temp_data["movieInfoResult"]["movieInfo"]["genres"]!= []:
movie_df.at[i, "Genere"] = temp_data["movieInfoResult"]["movieInfo"]["genres"][0]["genreNm"]
else:
movie_df.at[i, "Genere"] ="장르X"
# 배우수
if temp_data["movieInfoResult"]["movieInfo"]["actors"] != []:
movie_df.at[i, "ActNum"] = len(temp_data["movieInfoResult"]["movieInfo"]["actors"])
movie_df.at[i, "ActName"] = temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["peopleNm"]
movie_df.at[i, "ActCast"] = temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["cast"]
else:
movie_df.at[i, "ActNum"] =0
movie_df.at[i, "ActName"] =""
movie_df.at[i, "ActCast"] =""
print("*"*80)
# 출력 생략
movie_df.head(10)
# 출력 생략
movie_df.tail(10)
# 출력 생략
# +++ 에러에 대한 부분을 추가적으로 해야 함!!!!
# ==> 에러에 대한 원인 & 에러에 대한 판별 조건 발견!!
# json : 처음부터 ~~~원하는 정보가 있을 때 까지...한 단계씩 진행!!!!
# ---> 코드가 길어지는 귀찮은 점이 발생을 함!!!!
# +++ 메뉴얼을 보고, 본인이 원하는 정보를 요청할 수 있는 주소를 생성하는 것!!!!
*** 스스로 kobis api 메뉴얼만 보고
*** 통신, json 처리하는 부분 참고,,
==> 직접 한 번 해보세요!
*** 내일 오시기 전까지 꼭 ! 해보세요 !
kobis api 꼭! 스스로 해보기!!!!!!!
오늘 배운 내용은 안보고 할 줄 알아야 한다!!!
실습 많이 하자!!
나만의 실습 자료 만들기!!
//파이썬 - 양/늑대 문제
*** [ 나 지금, 지금에 연결된 곳들, 양, 늑대]
+++ 지금 양 보다 커지면 : 갱신,,
아니면 말고...
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 12일차 - 2 (24.12.19) (1) | 2024.12.19 |
|---|---|
| ASAC 빅데이터 분석가 과정 12일차 - 1 (24.12.19) (2) | 2024.12.19 |
| ASAC 빅데이터 분석가 과정 11일차 - 1 (24.12.18) (0) | 2024.12.18 |
| ASAC 빅데이터 분석가 과정 10일차 - 3 (24.12.17) (0) | 2024.12.17 |
| ASAC 빅데이터 분석가 과정 10일차 - 2 (24.12.17) (0) | 2024.12.17 |