03_pandas
00_code
08_dart_site
- 목적 : API명확하게 서로 데이터를 주고 받을려고 만든 프로토콜
(API : Application Programming Interface)
(소프트웨어 애플리케이션이 서로 통신하여 데이터를 교환할 수 있도록 하는 규칙이나 프로토콜)
- 통신 http을 활용해서, 정의된 api 서버에 접속하고 요청할 수 있다.
=> 접속하는 부분에서 코드로 서버에 접속을 해도 별 문제 없다. (빠르게 요청 가능)
=> 단, 하루에 할당량에 대한 제한이 있다. - api가 아닌 일반적인 사이트에서 원하는 정보가 있다
- 많은 시간들을 투자해서 사이트의 구조와 어떤 정보들을 주고 받는지 체크해야 한다 - 내가 원하는 정보에 대한 명확한 사이트의 주소를 파악해야 한다.
(눈에 보이는 주소 그대로 사용하면 된다)
(눈에 안 보이는 경우들을 내부적으로 어떻게 호출하고 받는지 정보를 뒤져서 파악해야 한다)
- 기능적인 체크
1) 숨겨져 있는 주소는 찾기 ===> 브라우저의 '개발자도구'
(개발자 도구 : 주소를 바탕으로 브라우저를 직접 컨트롤 하는 "셀레니움")
2) 대상이 일반적인 웹사이트 : html 속에서 필요한 정보들을 추출할 수 있다.
(ex. bs4의 BeautifulSoup)
3) 전체 페이지를 돌려가면서 하는 과정 (롤링)
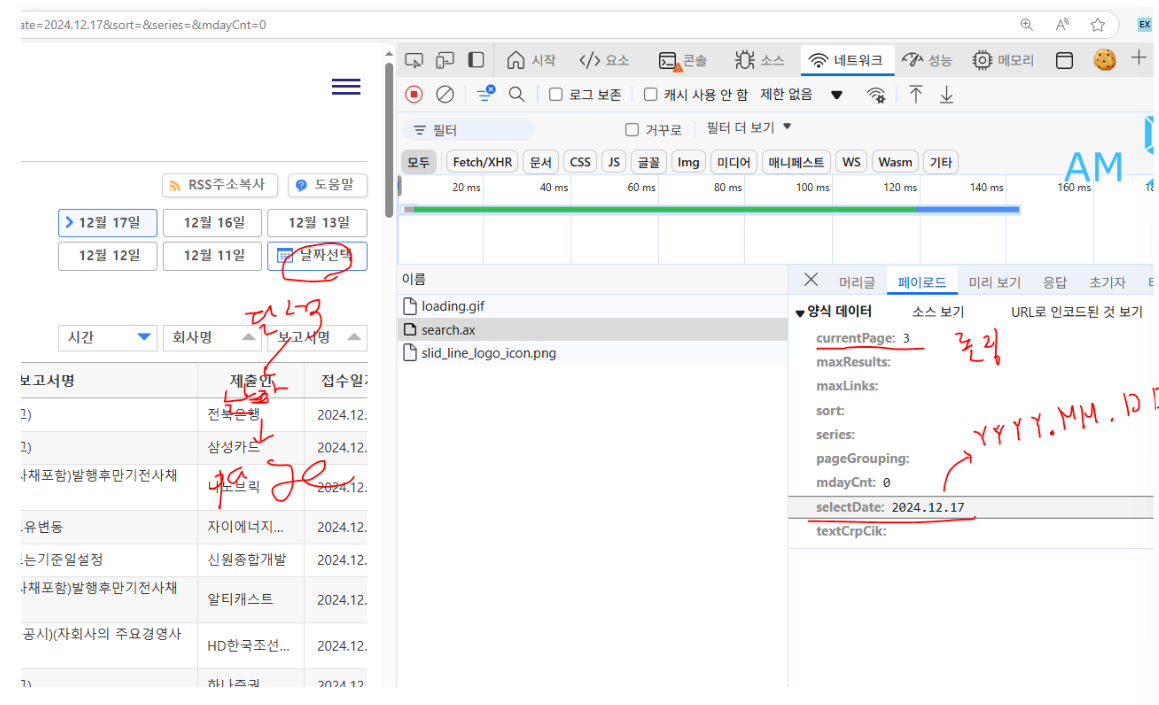
- 웹브라우저 개발자도구 : 네트워크쪽을 탐색
- 실제 사이트와 내 브라우저 사이에 주고 받은 정보들을 나타내고 있다
- 원하는 정보를 어떻게 주고 받았는지 열심히 찾아내야 한다
( 되는 지 안 되는 지 체크해야 한다)
- 여러 번 시도, 여러 사이트를 하면서 그때 그때 적응해서 하는 방법이 있다 - fcebook, instgram : 주기적으로 처리하는 방법이 변경
=> 코드적으로 데이터 수집을 어렵게 하기 위해서 자주 변경한다
=> 전체 정보에 대한 배치 규칙도 랜덤하게 배치한다
- 개인 프로젝트하실 때 상당히 잘 체크해야 한다 - Dart : 주소만 찾아내면 워하는 정보에 대한 페이지 접속할 수 있다
baseurl : https://dart.fss.or.kr/dsac001/search.ax
+ currentPage:
+ selectDate : YYYY.MM.DD
=> 조립
https://dart.fss.or.kr/dsac001/search.ax?selectDate=2024.12.17¤tPage=3
https://dart.fss.or.kr/dsac001/mainAll.do?selectDate=2024.12.17¤tPage=3 - => Dart의 주소를 생성하는 규칙
원하는 날짜와 페이지의 공시 정보들을 가지고 오는 직접적인 주소에 대해서 추론을 한다
api에서 처럼 요청하는 직접적인 주소다
- 할 일 : 특정 날짜에 대한 공시 정보를 DF으로 담아보자
=> 특정 기간에 대해서 공시 정보를 수집하는 함수/클래스 설계 - 필요한 패키지
1) 통신 : urllib, requests etc
import requests
2) 일반적인 사이트 양식 :html (tag 중심의 표현 언어)
html에서 내가 원하는 정보가 어느 tag에 있는지 : bs4
from bs4 import BeautifulSoup
3) 데이터 처리
import pandas as pd
4) 데이터를 처리하는 과정에 : 정규식, 시간에 대한 지연 처리
import re
import time
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import time
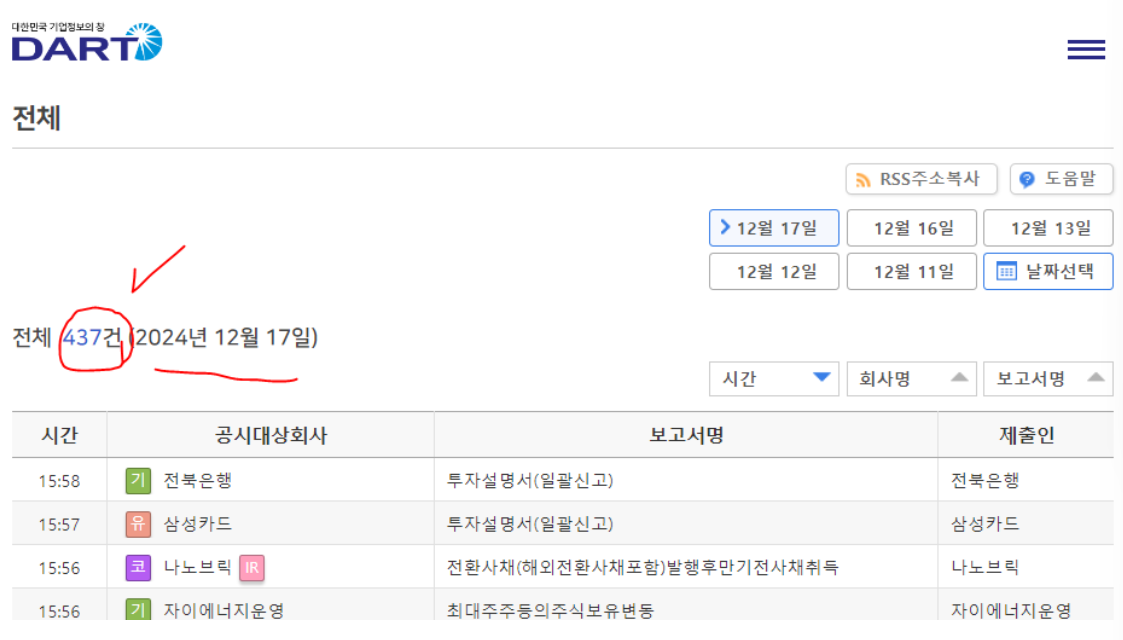
- Step1) 예시 날짜 : 2024.12.17
=> 437건의 모든 공시 정보를 요청해서 DF에 담아두자
=> 1페이지부터 5페이지까지 모두 다 처리하자
=> 페이지 롤링을 하자
date ="2024.12.17"
page ="1"
url = f"https://dart.fss.or.kr/dsac001/mainAll.do?selectDate={date}¤tPage={page}"
url
'https://dart.fss.or.kr/dsac001/mainAll.do?selectDate=2024.12.17¤tPage=1'
- Step2) 주소가 완성이 되었으니 직접 코드상에서 http통신 설계
=> requests 패키지 사용
(FM 방법 : dict으로 해서 보내기)
res =requests.get( url )
res
<Response [200]>
- 참고) request 패키지를 통해서 받은 정보를 열어보는 방식 2가지
1) res.text : 알아서 자기가 인코딩/디코딩 처리 (특별히 신경쓸 부분이 없다)
2) res.content : 이미지, 동영상
=> 바이트 값으로 들어온다
+ res.json() : json파일을 파이썬의 기본 자료형으로 자동 변경한다
=> 일반적인 사이트 : .text
특별하게 이미지/동영상 : .content
+ api에서 json으로 요청 : .json()
res.text # 코드의 정체 : 문자열
# 출력 생략
- 위의 요청한 정보들을 tag 중심으로 접근을 편히하기 위해서 BS4를 사용하면 편하다
=> 쌩텍스트 중심으로 원하는 정보를 찾을려면 re
=> tag, 중심으로 원하는 정보를 찾을려면 bs4
soup = BeautifulSoup( res.text, "html.parser")
soup
# 출력 생략
- => 요청한 페이지에 대한 html에 대한 정보가 soup 변수 1개에 담겨져 있다
+ bs4로 처리가 된 이후에 담겨져 있다
=> 필요한 정보를 tag 중심으로 접근해서 찾아내면 된다
- 참고) 내가 원하는 정보다 xml처럼 tag 사이에 있을 수도 있다
=> find, find_all() : tag 중심으로 찾아내면 된다 - 참고) 내가 원하는 정보가 tag속의 속성 값으로 존재할 수도 있다
(soup.find_all("div"))
# 출력 생략
len(soup.find_all("div"))
59
- 방법1) dict를 활용해서 tag 이외에 속성과 속성값을 지정한다
=> tag, 속성, 속성값 : 중심으로 타겟팅
soup.find_all("div", {"class":"headTitle"})
[<div class="headTitle">
<h3 id="subTitle"></h3>
<ul class="navy" id="path">
</ul>
</div>]
- 방법2) tag의 속성 중에서 bs4가 이미 파라미터들로 만들어둔 것들이 있다
=> class 속성에 class_ 파라미터로 만들어 두자
soup.find_all("div", class_="headTitle")
[<div class="headTitle">
<h3 id="subTitle"></h3>
<ul class="navy" id="path">
</ul>
</div>]
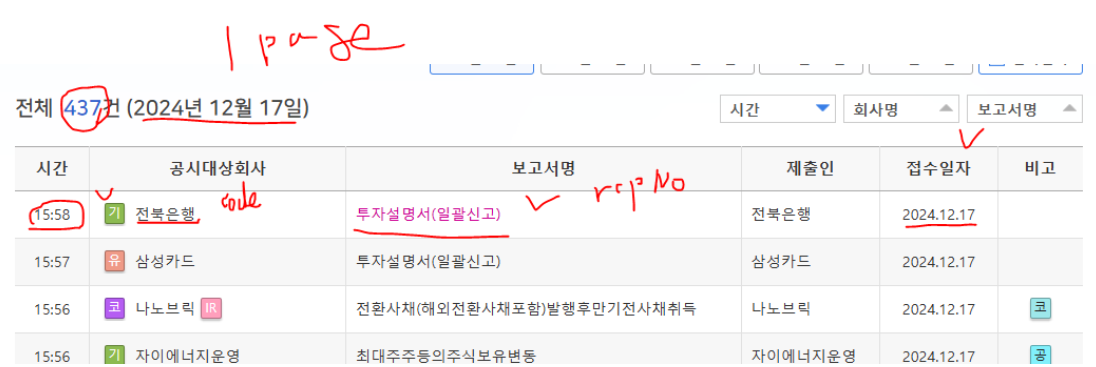
- Q) 전체 그 날의 공시 자료의 수를 체크
=> 내가 몇 페이지를 롤링할지 계산
=> 정규식을 사용해서 밑에 있는 공시 숫자에 대해서 처리하고자 한다
테이블 아래 [3/5] [총 437건] 이 정보에서 처리하고자 한다
--> [3/5] [총 437건] 정보를 접근해서 가져온다
temp = soup.find_all("div",{"class":"pageInfo"})[0].text
temp
'[1/5] [총 437건]'
- 참고) 필요한 부분에 대한 정보 추출 : 정규식
=> 정규식에서 문자열 패턴에 대해서 찾을 떄 : re.findall(패턴, 어디서)
=> 정규식으로 무엇을 무엇으로 변경할 때 : re.sub(패턴, 무엇으로변경, 어디서) - try1) 찾을 패턴/규칙 : 숫자들(1자~3자~4자리)+건
temp = re.findall( r"\d+건", temp)[0] # "437건"
temp = re.sub(r"건", "", temp) # "437"
temp
'437'
- => 위의 temp의 값을 가지고, 내가 몇 페이지를 돌려야 할지 계산한다
=> 페이지별로 최대 100건 공시를 보여준다고 가정하면
- 100으로 나눠서 몫을 올림한다
- 100 --> 1페이지 : 100/100 = 1
- 101 --> 2피이지 : 101/100 = 1.XXXX ---> 올림 : 2
if int(temp) % 100 ==0:
tot_page = int(temp) // 100
else:
tot_page = int(temp) // 100 + 1
tot_page
5
- 참고) 예전에 코테 : '주차요금'에서 올림 사용해서 했을 떄와 유사하다
(직접 코드로 구현해도 되고, 올림 패키지 사용해도 된다)
- Try2) 이번에는 아래 정보에서 페이지 수!!!
temp = soup.find_all("div",{"class":"pageInfo"})[0].text
temp
'[1/5] [총 437건]'
- 정규식에서 패턴 구별 : 정규식이 미리 사용하겠다고 지정한 문자 or 특수문자
[0-9], [a-z] : [ , ] 문자들이 묶음을 나타내는 정규식에 사용된다
=> 정규식에 지정된 기능이 아니라 단순 특수문자로 사용하기 위해서는 \ ( 파이썬 문자열) 사용
temp = re.findall(r"/\d+\]", temp)[0] # /5]
temp
'/5]'
실습) 필요한 공시 정보들에 대한 추출
- Q) 1개 공시에 대한 정보가 몇개 인지
이 페이지에 담겨져 있는 공시 정보의 수가 몇개 인지
len(soup.find_all("tr")
101
- => 순수하게 공시 100개 아니라, 테이블의 head에 있는 줄도 포함
len(soup.find("tbody").find_all("tr"))
100
- Q1) 1번 공시에 대한 정보를 접근하자
soup.find("tbody").find_all("tr")[0]
# 출력 생략
idx = 0 # 보려는 공시의 위치 인덱스 임의로 설정
temp = soup.find("tbody").find_all("tr")[idx]
temp
# 출력 생략
- Q2) 1번 공시에 대한 제출 시간을 출력하자
(안 좋은 공시들은 : 주말, 금요일 장 끝나는 시간으로 그때그때 다르다)
temp.find_all("td")[0]
# 출력 생략
temp.find_all("td")[0].text
\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t18:47\r\n\t\t\t\t\t\t\t
- 참고) 원하는 정보가 있지만 하다보면 눈에 안 보이던 공백들이 있다
=> 공백에 대한 문자 제거 필요
sol1) .strip() : 양쪽에 공백을 제거 -> 중간에 공백이 있으면 오류
sol2) 정규식 --> 제거
" 18:47 " -> .strip() : "18:47"
" 18: 47 " => .strip() : "18: 47" -> 정규식으로 해야 한다
t_str1= "\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t18:47\r\n\t\t\t\t\t\t\t"
t_str1
'\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t18:47\r\n\t\t\t\t\t\t\t'
print(t_str1)
18:47
t_str1.strip()
'18:47'
t_str2= "\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t18:\n\n\n\n47\r\n\t\t\t\t\t\t\t"
t_str2
'\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t\t18:\n\n\n\n47\r\n\t\t\t\t\t\t\t'
print(t_str2)
18:
47
t_str2.strip()
'18:\n\n\n\n47'
re.sub(r"\r|\n|\t|\s", "", t_str2)
18:47
- => 해당하는 공백이 어디에 있더러다도 다 제거하는 정규식이다.
# 1번 공시 시간
temp.find_all("td")[0].text.strip()
'18:47'
- Q3) 1번 공시에 대한 제출한 회사가 속한 시장을 출력하자
예) 코 : 코스닥, 유:유가a증권, 넥:코넥스, 기 : 기타법인
=> 원하는 정보가 tag의 속성값에 존재할 때 어떻게 접근할지 고민 필요
temp.find_all("td")[1].find_all("span")[1].text
'코'
temp.find_all("td")[1].find_all("span")[1]
<span class="tagCom_kosdaq" style="cursor:default" title="코스닥시장">코</span>
temp.find_all("td")[1].find_all("span")[1].get("title")
'코스닥시장'
- Q4) 1번 공시에 대한 회사의 이름을 출력하자
temp.find_all("td")[1].text # 속한 시장과 회사명이 혼재가 된다
# 최대한 내가 원하는 정보가 있는 것에 밀접하게 접근하
'\n\n코\n\r\n\t\t\t\t\t\t\t\t\t\t비덴트\r\n\t\t\t\t\t\t\t\t\t\n\n'
temp.find_all("td")[1].text.strip()
'코\n\r\n\t\t\t\t\t\t\t\t\t\t비덴트'
temp.find_all("td")[1].text.strip()[1:].strip()
'비덴트'
temp.find_all("td")[1].find("a").text.strip()
'비덴트'
- # Q5) 1번 공시에 대한 회사의 코드값을 출력하자

- => 필요한 정보 : tag 안의 속성값에 존재
=> 속성값에서 0-9까지 숫자가 연속으로 8개 이어진 규칙을 만족
temp.find_all("td")[1].find("a").get("href")
javascript:openCorpInfoNew('00693651', 'winCorpInfo', '/dsae001/selectPopup.ax');
re.findall(r"\d{8}",
temp.find_all("td")[1].find("a").get("href"))[0]
'00693651'
re.findall(r"[0-9]{8}",temp.find_all("td")[1].find("a").get("href"))[0]
# ---> 숫자 범위에 대한 조작이 용이함!!!
'00693651'
- Q1) 1번 공시의 공시 이름을 출력하자
temp.find_all("td")[2].text.strip() #빈 구간이 존재함
'기타시장안내\r\n\t\t\t\t\t\t\t\t\t\r\n\t\t \t\t\t\t\t\t\t(상장적격성 실질심사 사유 추가 관련 절차 미진행)'
re.sub(r"\n|\t|\r", "", temp.find_all("td")[2].text.strip())
# 참고.re.sub(r"\n|\t|\s|\r", "", temp.find_all("td")[2].text.strip())
'기타시장안내 (상장적격성 실질심사 사유 추가 관련 절차 미진행)'
- Q2) 1번 공시에 대한 고유값 rcpNo 구하자
temp.find_all("td")[2].find("a").get("href")
'/dsaf001/main.do?rcpNo=20241217900785'
re.findall(r"\d{14}",temp.find_all("td")[2].find("a").get("href") )[0]
'20241217900785'
- Q3) 1번 공시에 대한 접수일자를 구하자
temp.find_all("td")[4].text
'2024.12.17'
- Q1) for문을 이용해서 이 페이지에 있는 100건을 다 롤링해서 제대로 출력이 되는지 체크하자
=> 제출시간, 회사가속한시장, 회사이름, 회사코드값, 공시이름, 공시rcpno, 요청일자
# 방법 1) 단순 출력
tot_cnt = len(soup.find("tbody").find_all("tr"))
# 정수 인덱스 중심으로 돌린다
for idx in range(tot_cnt):
temp = soup.find("tbody").find_all("tr")[idx]
# 1개 공시에 대한 전체 정보
print(temp.find_all("td")[0].text.strip() )
print(temp.find_all("td")[1].find_all("span")[1].get("title"))
print(temp.find_all("td")[1].find("a").text.strip())
print(re.findall(r"\d{8}", temp.find_all("td")[1].find("a").get("href"))[0])
print(re.sub(r"\n|\t|\r", "", temp.find_all("td")[2].text.strip()))
print(re.findall(r"\d{14}",temp.find_all("td")[2].find("a").get("href") )[0])
print(temp.find_all("td")[4].text)
print("*"*80)
18:47
코스닥시장
비덴트
00693651
기타시장안내 (상장적격성 실질심사 사유 추가 관련 절차 미진행)
20241217900785
2024.12.17
********************************************************************************
18:30
코스닥시장
아시아종묘
00867478
매출액또는손익구조30%(대규모법인은15%)이상변동
20241217900782
2024.12.17
...#출력 생략
# 방법 2
for i, temp in enumerate( soup.find("tbody").find_all("tr") ):
# 가로줄을 정수 인덱스 중심으로 돌린다
# temp = soup.find("tbody").find_all("tr")[idx]
# 1개 공시에 대한 전체 정보
print(f"{i+1}번째 공시 정보")
print(temp.find_all("td")[0].text.strip() )
print(temp.find_all("td")[1].find_all("span")[1].get("title"))
print(temp.find_all("td")[1].find("a").text.strip())
print(re.findall(r"\d{8}", temp.find_all("td")[1].find("a").get("href"))[0])
print(re.sub(r"\n|\t|\r", "", temp.find_all("td")[2].text.strip()))
print(re.findall(r"\d{14}",temp.find_all("td")[2].find("a").get("href") )[0])
print(temp.find_all("td")[4].text)
print("*"*80)
18:47
코스닥시장
비덴트
00693651
기타시장안내 (상장적격성 실질심사 사유 추가 관련 절차 미진행)
20241217900785
2024.12.17
********************************************************************************
18:30
코스닥시장
아시아종묘
00867478
매출액또는손익구조30%(대규모법인은15%)이상변동
20241217900782
2024.12.17
...#출력 생략
- Q2) 위에서 출력한 내용들을 DF에 저장하자
(컬럼 이름, 담는 스타일은 마음대로 하자)
# 1페이지에 있는 모든 공시 정보를 DF으로 저장
# soup : 2024.12.17일의 1페이지 공시 정보들만 존재
dart_data = []
for i, temp in enumerate( soup.find("tbody").find_all("tr") ):
d_time= temp.find_all("td")[0].text.strip()
d_market = temp.find_all("td")[1].find_all("span")[1].get("title")
d_co_name = temp.find_all("td")[1].find("a").text.strip()
d_co_id = re.findall(r"\d{8}", temp.find_all("td")[1].find("a").get("href"))[0]
d_rcp_name = re.sub(r"\n|\t|\r", "", temp.find_all("td")[2].text.strip())
d_rcp_no = re.findall(r"\d{14}",temp.find_all("td")[2].find("a").get("href") )[0]
d_req = temp.find_all("td")[4].text
# ==> 출력했던 정보들에 대한 변수화!!!!!!
dart_data.append( [d_time, d_market, d_co_name,d_co_id,
d_rcp_name,d_rcp_no,d_req])
print("Done!!!")
Done!!!
len(dart_data)
100
df_1 = pd.DataFrame(
data = dart_data,
columns = ["time","market","co_name","co_id",
"report_name","report_code","req_date"]
)
df_1

df_1.to_csv("2024_12_17_p1.csv", sep=",")
- Q3) 2024년 12월 17일에 대한 437건의 모든 공시에 대해서 모든 공시 437건을 모두 DF에 담아보자
date ="2024.12.17"
page ="1"
url = f"https://dart.fss.or.kr/dsac001/mainAll.do?selectDate={date}¤tPage={page}"
res = requests.get(url) # FM으로 하려면 방응에 대한 에러 처리...
soup = BeautifulSoup( res.text, "html.parser")
# => 이 중에서 몇 페이지를 돌려야 할지 체크하자
# 그냥 1부터 쏘면서, 결과가 없으면 쫑하는 방법 (앞에서 했던 코드 살리기 위해)
tot_page = soup.find_all('div', {"class":"pageInfo"})[0].text
tot_page = re.findall(r"/\d+\]", tot_page)[0]
tot_page = re.sub(r"/|\]", "", tot_page)
tot_page = int(tot_page)
# 2) 전체 페이지에 대해서 요청하는 url을 생성 : 1~~~5페이지
dart_data = []
for page in range(1, tot_page+1):
url = f"https://dart.fss.or.kr/dsac001/mainAll.do?selectDate={date}¤tPage={page}"
res = requests.get(url) # FM으로 하려면 방응에 대한 에러 처리...
soup = BeautifulSoup( res.text, "html.parser")
# i번째 page에서 할 일 : 그 페이지에 있는 여러 개의 공시정보 처리
for i, temp in enumerate( soup.find("tbody").find_all("tr") ):
d_time= temp.find_all("td")[0].text.strip()
d_market = temp.find_all("td")[1].find_all("span")[1].get("title")
d_co_name = temp.find_all("td")[1].find("a").text.strip()
d_co_id = re.findall(r"\d{8}", temp.find_all("td")[1].find("a").get("href"))[0]
d_rcp_name = re.sub(r"\n|\t|\r", "", temp.find_all("td")[2].text.strip())
d_rcp_no = re.findall(r"\d{14}",temp.find_all("td")[2].find("a").get("href") )[0]
d_req = temp.find_all("td")[4].text
# 출력했던 정보들에 대한 변수화
dart_data.append( [d_time, d_market, d_co_name,d_co_id,
d_rcp_name,d_rcp_no,d_req])
print(f"{page}공시 정보 {i+1}개 처리 완료!!!!")
1공시 정보 100개 처리 완료!!!!
2공시 정보 100개 처리 완료!!!!
3공시 정보 100개 처리 완료!!!!
4공시 정보 100개 처리 완료!!!!
5공시 정보 37개 처리 완료!!!!
df_2 = pd.DataFrame(
data = dart_data,
columns = ["time","market","co_name","co_id",
"report_name","report_code","req_date"]
)
df_2.head()

len(df_2)
437
df_2.to_csv("2024_12_17_tot.csv", sep=",")
- 참고) dart_tot 리스트에 원소가 많이 들어가서 속도 저하가 발생을 할 때
중간 중간에 file이나 로컬로 저장을 하고, 리스트를 중간 중간 비워가면서 채우시는 것을 추천
=>중간에 하시면서 시간이나 딜레이 이런 부분을 보면서 해보자 - 정리
- 가장 편한 방법 : api ( 메뉴얼을 보고, 내가 필요한 사항에 대한 요청을 직접 만들어서 보내야 함!!!! )
- 내가 원하는 정보가 웹사이트
- 내가 원하는 정보에 바로 접근할 수 있는 url: 개발자도구
+ 안 되는 경우 => 우회방법
=> 웹브라우저를 통해서 접근(속도가 많이 느리기 때문에)
반응형
'ASAC 빅데이터 분석가 7기 > ASAC 일일 기록' 카테고리의 다른 글
| ASAC 빅데이터 분석가 과정 15일차 - 1 (24.12.24) (0) | 2024.12.24 |
|---|---|
| ASAC 빅데이터 분석가 과정 14일차 - 2 (24.12.23) (0) | 2024.12.23 |
| ASAC 빅데이터 분석가 과정 12일차 - 2 (24.12.19) (1) | 2024.12.19 |
| ASAC 빅데이터 분석가 과정 12일차 - 1 (24.12.19) (2) | 2024.12.19 |
| ASAC 빅데이터 분석가 과정 11일차 - 2 (24.12.18) (2) | 2024.12.18 |